Self-supervised Learning for Speech and Audio Processing I
Technical Program Session MLSP-3
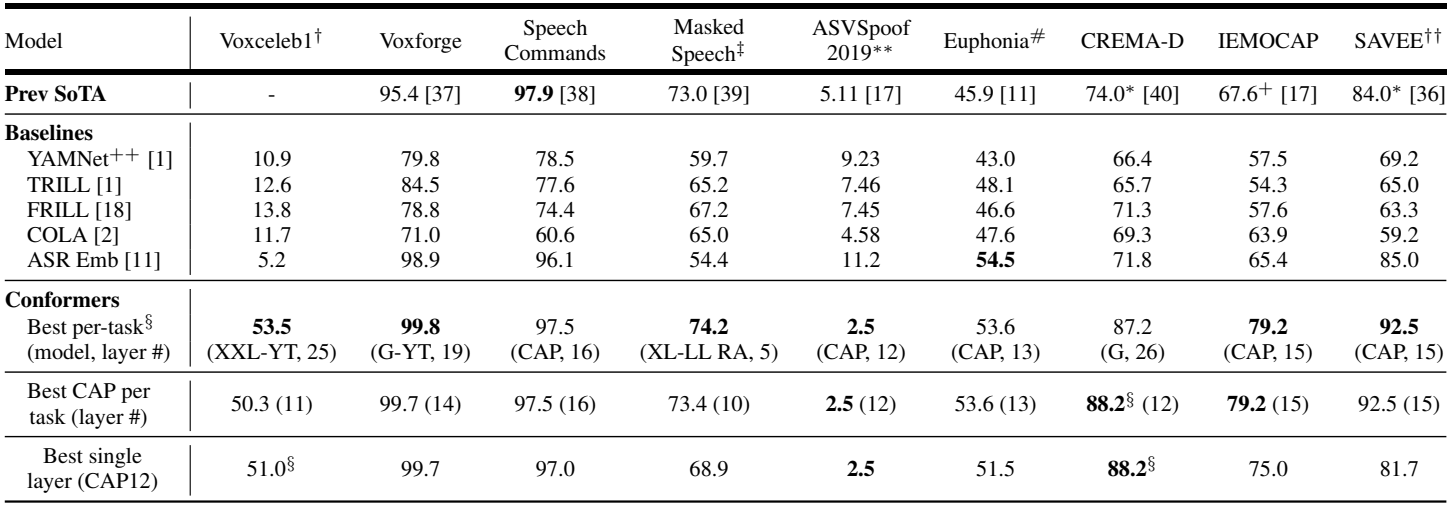
UNIVERSAL PARALINGUISTIC SPEECH REPRESENTATIONS USING SELF-SUPERVISED CONFORMERS
Verily Life Sciences, Boston, USA1 and Mountain View, California, USA
Many speech applications require understanding aspects beyond the words being spoken, such as recognizing emotion, detecting whether the speaker is wearing a mask, or distinguishing real from synthetic speech. In this work, we introduce a new state-of-the-art paralinguistic representation derived from large-scale, fully self-supervised training of a 600M+ parameter Conformer-based architecture. We benchmark on a diverse set of speech tasks and demonstrate that simple linear classifiers trained on top of our time-averaged representation outperform nearly all previous results, in some cases by large margins. Our analyses of context-window size demonstrate that, surprisingly, 2 second context-windows achieve 96% the performance of the Conformers that use the full long-term context on 7 out of 9 tasks. Furthermore, while the best per-task representations are extracted internally in the network, stable performance across several layers allows a single universal representation to reach near optimal performance on all tasks.
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9747197
-
Proposed method
-
Key Findings
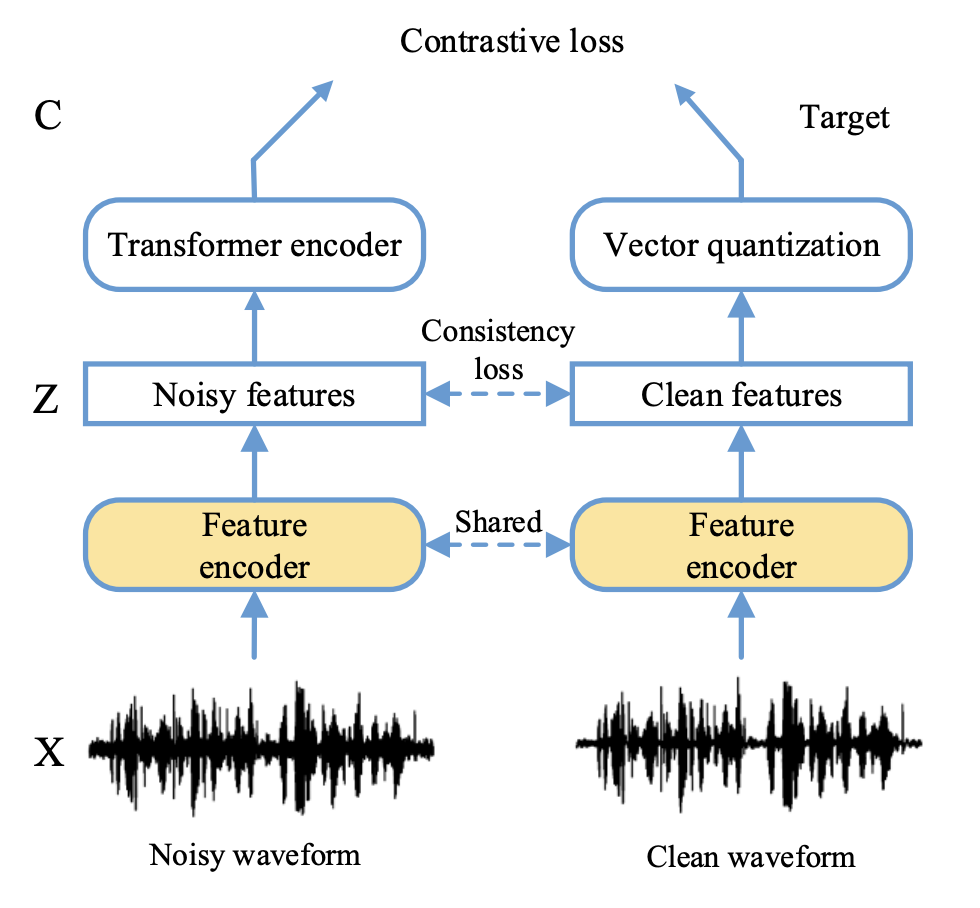
A NOISE-ROBUST SELF-SUPERVISED PRE-TRAINING MODEL BASED SPEECH REPRESENTATION LEARNING FOR AUTOMATIC SPEECH RECOGNITION
NEL-SLIP, University of Science and Technology of China (USTC), Hefei, China
Wav2vec2.0 is a popular self-supervised pre-training framework for learning speech representations in the context of automatic speech recognition (ASR). It was shown that wav2vec2.0 has a good robustness against the domain shift, while the noise robustness is still unclear. In this work, we therefore first analyze the noise robustness of wav2vec2.0 via experiments. We observe that wav2vec2.0 pre-trained on noisy data can obtain good representations and thus improve the ASR performance on the noisy test set, which however brings a performance degradation on the clean test set. To avoid this issue, in this work we propose an enhanced wav2vec2.0 model. Specifically, the noisy speech and the corresponding clean version are fed into the same feature encoder, where the clean speech provides training targets for the model. Experimental results reveal that the proposed method can not only improve the ASR performance on the noisy test set which surpasses the original wav2vec2.0, but also ensure a tiny performance decrease on the clean test set. In addition, the effectiveness of the proposed method is demonstrated under different types of noise conditions.
https://ieeexplore.ieee.org/document/9747379
AN ADAPTER BASED PRE-TRAINING FOR EFFICIENT AND SCALABLE SELF-SUPERVISED SPEECH REPRESENTATION LEARNING
Huawei R&D UK, University of Oxford
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9747374
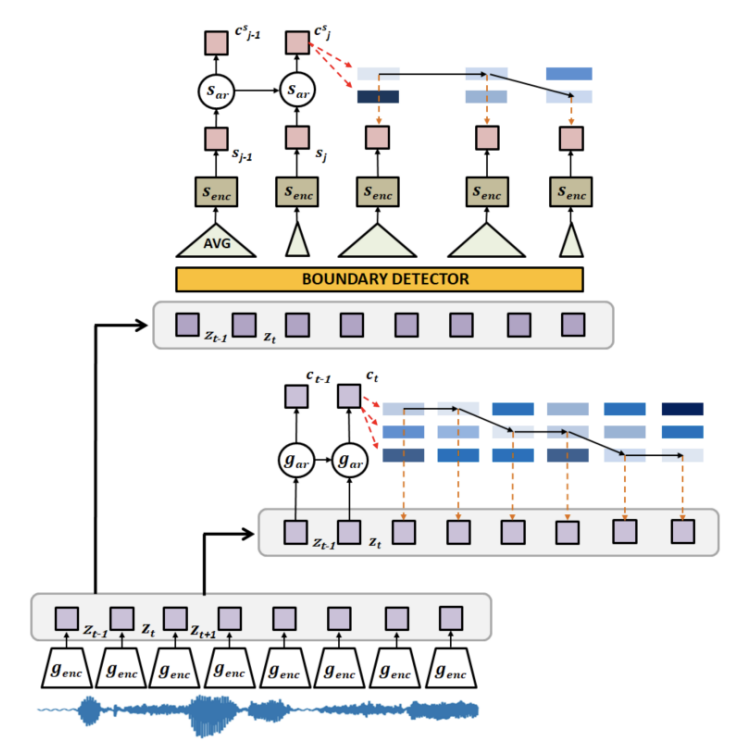
CONTRASTIVE PREDICTION STRATEGIES FOR UNSUPERVISED SEGMENTATION AND CATEGORIZATION OF PHONEMES AND WORDS
University of Wroclaw, Poland, NavAlgo, France, NVIDIA, Poland, Universite de Toulon, France
We identify a performance trade-off between the tasks of phoneme categorization and phoneme and word segmentation in several self-supervised learning algorithms based on Contrastive Predictive Coding (CPC). Our experiments suggest that context building networks, albeit necessary for high performance on categorization tasks, harm segmentation performance by causing a temporal shift on the learned representations. Aiming to tackle this trade-off, we take inspiration from the leading approaches on segmentation and propose multi-level Aligned CPC (mACPC). It builds on Aligned CPC (ACPC), a variant of CPC which exhibits the best performance on categorization tasks, and incorporates multi-level modeling and optimization for detection of spectral changes. Our methods improve in all tested categorization metrics and achieve state-of-the-art performance in word segmentation.
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9746102
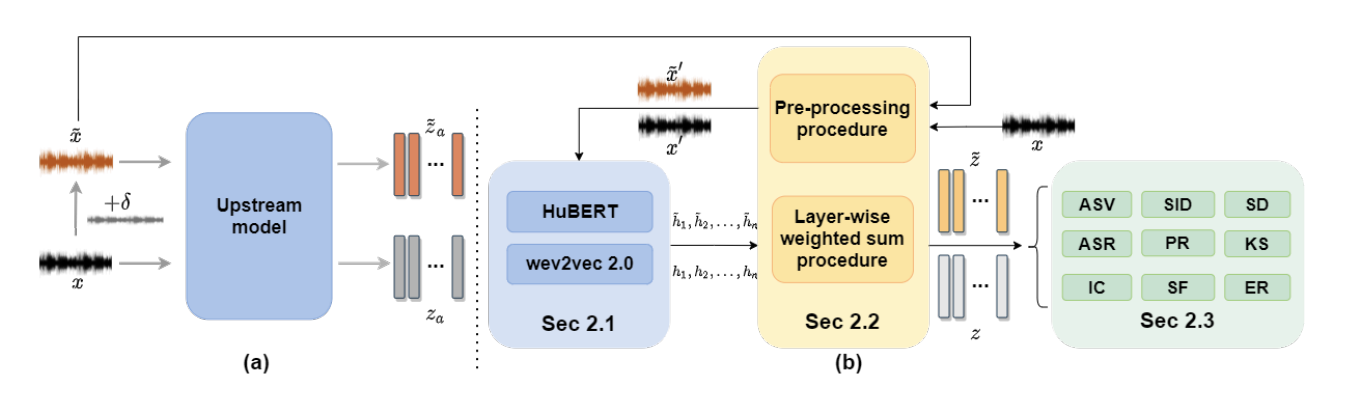
CHARACTERIZING THE ADVERSARIAL VULNERABILITY OF SPEECH SELF-SUPERVISED LEARNING
National Taiwan University, The Chinese University of Hong Kong
SUPERB
A leaderboard named Speech processing Universal PERformance Benchmark (SUPERB), which aims at benchmarking the performance of a shared self-supervised learning (SSL) speech model across various downstream speech tasks with minimal modification of architectures and a small amount of data, has fueled the research for speech representation learning. The SUPERB demonstrates speech SSL upstream models improve the performance of various downstream tasks through just minimal adaptation. As the paradigm of the self-supervised learning upstream model followed by downstream tasks arouses more attention in the speech community, characterizing the adversarial robustness of such paradigm is of high priority. In this paper, we make the first attempt to investigate the adversarial vulnerability of such paradigm under the attacks from both zero-knowledge adversaries and limited-knowledge adversaries. The experimental results illustrate that the paradigm proposed by SUPERB is seriously vulnerable to limited-knowledge adversaries, and the attacks generated by zero-knowledge adversaries are with transferability. The XAB test verifies the imperceptibility of crafted adversarial attacks.
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9747242