Speech Recognition: Robust Speech Recognition I
Technical Program Session SPE-2
AUDIO-VISUAL MULTI-CHANNEL SPEECH SEPARATION, DEREVERBERATION AND RECOGNITION
The Chinese University of Hong Kong; Tencent AI lab
Problem
accurate recognition of cocktail party speech characterised by the interference from overlapping speakers, background noise and room reverberation.
Proposed method
In this paper, an audiovisual multi-channel speech separation, dereverberation and recognition approach with visual information into all three stages of the system is proposed.
The advantage of the additional visual modality over using audio only is demonstrated on two neural dereverberation approaches based on DNN-WPE and spectral mapping respectively.

BEST OF BOTH WORLDS: MULTI-TASK AUDIO-VISUAL AUTOMATIC SPEECH RECOGNITION AND ACTIVE SPEAKER DETECTION
Google, Inc.
Problem
Under noisy conditions, automatic speech recognition (ASR) can greatly benefit from the addition of visual signals coming from a video of the speaker’s face.
현실적으로 여러 얼굴이 존재하는 경우가 많은데 전통적으로 active speaker detection (ASD)으로 모든 시간마다 audio와 일치하는 active speaker's face를 분리하는 모델을 따로 사용했으나, 최근에는 attention 모델을 추가해서 별도의 ASD를 설계하지 않고 audio와 모든 face candidate을 모델에 집어 넣어 end-to-end way로 처리 하기도 한다.
Proposed method
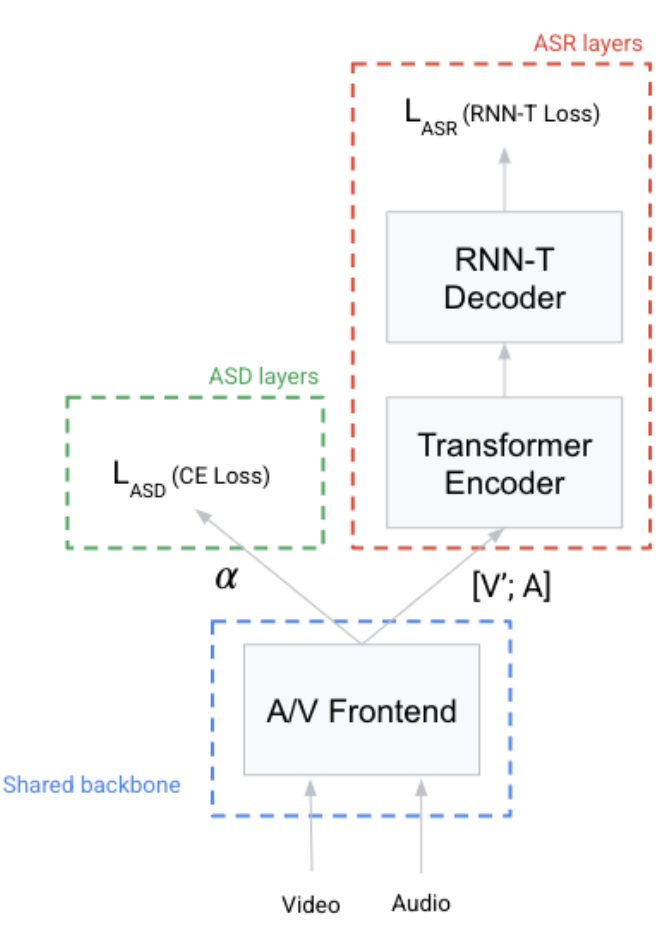
2.1. A/V Backbone: Shared Audio-Visual Frontend
Acoustic Features. log mel filterbank
Audio and Video Synchronization. resample video
Visual Features. ConvNet on top of the synchronized video
Attention Mechanism. in order to soft-select the one matching the audio.
2.2. ASR Model - Transformer-Transducer Model
For ASR, the weighted visual features and input acoustic features are then concatenated along the last dimension, producing audio-visual features which are then fed to the ASR encoder.
2.3. ASD Model
For ASD, the attention scores is used directly for the model prediction. For each audio query and each timestep, the attention scores give a measure of how well each candidate video corresponds to the audio.
3. MULTI-TASK LOSS FOR A/V ASR AND ASD
ASD. For active speaker detection, the normalized attention weights can be used to train the attention module directly with cross entropy loss.
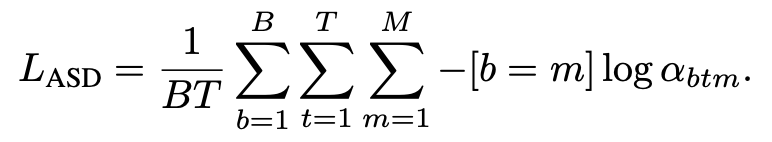
ASR. RNN-T loss
MTL Loss. We combine the ASD and ASR losses with a weighted linear sum of the losses
Key Findings
This paper presents a multi-task learning (MTL) for a model that can simultaneously perform audio-visual ASR and active speaker detection, improving previous work on multiperson audio-visual ASR.
Combining the two tasks is enough to significantly improve the performance of the model in the ASD task relative to the baseline.
IMPROVING NOISE ROBUSTNESS OF CONTRASTIVE SPEECH REPRESENTATION LEARNING WITH SPEECH RECONSTRUCTION
The Ohio State University, USA, Microsoft Corporation
Problem
Noise Robust ASR
Proposed method
In this paper, authors employ a noise-robust representation learned by a refined self-supervised framework of wav2vec 2.0 for noisy speech recognition. They combine a reconstruction module with contrastive learning and perform multi-task continual pre-training to explicitly reconstruct the clean speech from the noisy input.
