The most of the following contents are from the folloing link. This posting is just newly organized format of the huyenchip's posting so that it is easy for me to understand and remebmer.
Three steps to build production performance LLM
- Pretraining
- Supervised Fine-Tuning (SFT)
- Reinforcement Learning from Human Feedback (RLHF)

You can skip any of the three phases. For example, you can do RLHF directly on top of the pretrained model, without going through the SFT phase. However, empirically, combining all these three steps gives the best performance.
Pretraining is the most resource-intensive phase. For the InstructGPT model, pretraining takes up 98% of the overall compute and data resources. You can think of SFT and RLHF as unlocking the capabilities that the pretrained model already has but are hard for users to access via prompting alone.
Phase I. Pretraining
The result of the pretraining phase is a large language model (LLM), often known as the pretrained model. Examples include GPT-x (OpenAI), Gopher (DeepMind), LLaMa (Meta), StableLM (Stability AI).
Language Model
A language model encodes statistical information about language. For simplicity, statistical information tells us how likely something (e.g. a word, a character) is to appear in a given context. You can think of tokens as the vocabulary that a language model uses.
Fluent speakers of a language subconsciously have statistical knowledge of that language. For example, given the context My favorite color is __, if you speak English, you know that the word in the blank is much more likely to be green than car.
Mathematical formulation
- ML task: language modeling
- Training data: low-quality data
- Data scale: usually in the order of trillions of tokens as of May 2023.
- GPT-3’s dataset (OpenAI): 0.5 trillion tokens. No info for GPT-4
- Gopher’s dataset (DeepMind): 1 trillion tokens
- RedPajama (Together): 1.2 trillion tokens
- LLaMa’s dataset (Meta): 1.4 trillion tokens
- Model resulting from this process: LLM

Data for pre-training

A trillion token is: a book contains around 50,000 words or 67,000 tokens. 1 trillion tokens are equivalent to 15 million books.
Phase II. Supervised finetuning (SFT) for dialogue
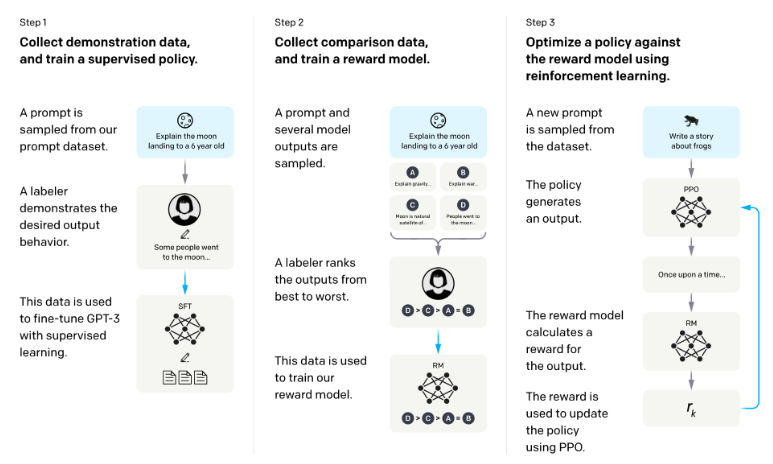
The goal of SFT is to optimize the pretrained model to generate the responses that users are looking for. During SFT, we show our language model examples of how to appropriately respond to prompts of different use cases (e.g. question answering, summarization, translation). The examples follow the format (prompt, response) and are called demonstration data. OpenAI calls supervised finetuning behavior cloning. OpenAI showed that the finetuned approach produces much superior results.

Demonstration data
Demonstration data can be generated by humans, like what OpenAI did with InstructGPT and ChatGPT. demonstration data is generated by highly educated labelers ( ~90% have at least a college degree and more than one-third have a master’s degree.) OpenAI’s 40 labelers created around 13,000 (prompt, response) pairs for InstructGPT.
Mathematical formulation
The mathematical formulation is very similar to the one in phase 1.
- ML task: language modeling
- Training data: high-quality data in the format of (prompt, response)
- Data scale: 10,000 - 100,000 (prompt, response) pairs
- InstructGPT: ~14,500 pairs (13,000 from labelers + 1,500 from customers)
- Alpaca: 52K ChatGPT instructions
- Databricks’ Dolly-15k: ~15k pairs, created by Databricks employees
- OpenAssistant: 161,000 messages in 10,000 conversations -> approximately 88,000 pairs
- Dialogue-finetuned Gopher: ~5 billion tokens, which I estimate to be in the order of 10M messages.
- Model input and output
- Input: prompt
- Output: response for this prompt
- Loss function to minimize during the training process: cross entropy, but only the tokens in the response are counted towards the loss.
Phase III. Reinforcement Learning from Human Feedback (RLHF)
Dialogues are flexible. Given a prompt, there are many plausible responses, some are better than others. Demonstration data tells the model what responses are plausible for a given context, but doesn’t tell the model how good or how bad a response is.
The idea: what if we have a scoring function that, if given a prompt and a response, outputs a score for how good that response is? Then we use this scoring function to further train our LLMs towards giving responses with high scores. That’s exactly what RLHF does. RLHF consists of two parts:
- Train a reward model to act as a scoring function.
- Optimize LLM to generate responses for which the reward model will give high scores.
Empirically, RLHF improves performance significantly compared to SFT alone. Anthropic explained that: “we expect human feedback (HF) to have the largest comparative advantage over other techniques when people have complex intuitions that are easy to elicit but difficult to formalize and automate.”
»»Side note: Hypotheses on why RLHF works««
Yoav Goldberg has an excellent note on the three hypotheses on why RLHF works.
- The diversity hypothesis: during SFT, the model’s output is expected to somewhat match the demonstrated responses. For example, given the prompt “what’s an example of a language?”, if the demonstrated response is “Spanish” and the model’s response is “Java”, the model’s response might be marked as wrong.
- The negative feedback hypothesis: demonstration only gives the model positive signals (e.g. only showing the model good responses), not negative signals (e.g. showing models what bad responses look like). RL allows us to show models negative signals.
- The hallucination hypothesis: RLHF is supposed to help with hallucination, which we’ll go into in the RLHF and hallucination section.
3.1. Reward model (RM)
The RM’s job is to output a score for a pair of (prompt, response). Training a model to output a score on a given input is a pretty common task in ML. You can simply frame it as a classification or a regression task. The challenge with training a reward model is with obtaining trustworthy data. Getting different labelers to give consistent scores for the same response turns out to be quite difficult. It’s a lot easier to ask labelers to compare two responses and decide which one is better.
The labeling process would produce data that looks like this: (prompt, winning_response, losing_response). This is called comparison data.

Mathematical formulation
There might be some variations, but here’s the core idea.
- Training data: high-quality data in the format of (prompt, winning_response, losing_response)
- Data scale: 100K - 1M examples
- InstructGPT: 50,000 prompts. Each prompt has 4 to 9 responses, forming between 6 and 36 pairs of (winning_response, losing_response). This means between 300K and 1.8M training examples in the format of (prompt, winning_response, losing_response).
- Constitutional AI, which is suspected to be the backbone of Claude (Anthropic): 318K comparisons – 135K generated by humans, and 183K generated by AI. Anthropic has an older version of their data open-sourced (hh-rlhf), which consists of roughly 170K comparisons.

3.2. Finetuning using the reward model
In this phase, we will further train the SFT model to generate output responses that will maximize the scores by the RM. Today, most people use Proximal Policy Optimization (PPO), a reinforcement learning algorithm released by OpenAI in 2017.
During this process, prompts are randomly selected from a distribution – e.g. we might randomly select among customer prompts. Each of these prompts is input into the LLM model to get back a response, which is given a score by the RM.
Mathematical formulation
- ML task: reinforcement learning
- Action space: the vocabulary of tokens the LLM uses. Taking action means choosing a token to generate.
- Observation space: the distribution over all possible prompts.
- Policy: the probability distribution over all actions to take (aka all tokens to generate) given an observation (aka a prompt). An LLM constitutes a policy because it dictates how likely a token is to be generated next.
- Reward function: the reward model.
- Training data: randomly selected prompts
- Data scale: 10,000 - 100,000 prompts
- InstructGPT: 40,000 prompts
RLHF and hallucination
Hallucination happens when an AI model makes stuff up. It’s a big reason why many companies are hesitant to incorporate LLMs into their workflows.
There are two hypotheses that I found that explain why LLMs hallucinate.
The first hypothesis, first expressed by Pedro A. Ortega et al. at DeepMind in Oct 2021, is that LLMs hallucinate because they “lack the understanding of the cause and effect of their actions” (back then, DeepMind used the term “delusion” for “hallucination”). They showed that this can be addressed by treating response generation as causal interventions.
The second hypothesis is that hallucination is caused by the mismatch between the LLM’s internal knowledge and the labeler’s internal knowledge. In his UC Berkeley talk (April 2023), John Schulman, OpenAI co-founder and PPO author, suggested that behavior cloning causes hallucination. During SFT, LLMs are trained to mimic responses written by humans. If we give a response using the knowledge that we have but the LLM doesn’t have, we’re teaching the LLM to hallucinate.
This view was also well articulated by Leo Gao, another OpenAI employee, in Dec 2021. In theory, the human labeler can include all the context they know with each prompt to teach the model to use only the existing knowledge. However, this is impossible in practice.
The most of the following contents are from the folloing link. This posting is just newly organized format of the huyenchip's posting so that it is easy for me to understand and remebmer.