- Accurate and timely recognition of the trigger keyword is vital.
- There is a trade-off needed between accuracy and latency.
Proposed method
- We propose an CRNN-based unified speculation, detection, and verification keyword detection model.
- We propose a latency- aware max-pooling loss, and show empirically that it teaches a model to maximize accuracy under the latency constraint.
- A USDV model can be trained in a MTL fashion and achieves different accuracy and latency trade-off across these three tasks.
1. Unified speculation, detection, and verification model
- Speculation makes an early decision, which can be used to give a head-start to downstream processes on the device.
- Detection mimics the traditional keyword trigger task and gives a more accurate decision by observing the full keyword context.
- Verification verifies previous decision by observing even more audio after the keyword span.
2. Model architecture and training strategy
- CRNN architecture
- multi-task learning with different target latencies on the new proposed latency-aware max-pooling loss.
Temporal Early Exiting for Streaming Speech Commands Recognition
Comcast Applied AI, University of Waterloo
Problem
Voice queries to take time to process:
Stage 1: The user is speaking (seconds).
Stage 2: Finish ASR transcription (~50ms).
Stage 3: Information retrieval (~500ms).
Proposed method
- Use a streaming speech commands model for the top-K voice queries.
- Apply some training objective for better early exiting across time; Return a prediction before the entire audio is observed.
- Use early exiting with some con dence threshold to adjust the latency-accuracy trade-off.
Model
- GRU Model
- Per-frame output probability distribution over K commands (classes).
Early-Exiting Objectives
Connectionist temporal classi cation (CTC):
Last-frame cross entropy (LF):
All-frame cross entropy (AF):
Findings
1. The all-frame objective (AF) performs best, perhaps because it explicitly trains the hidden features to be more discriminative, similar to deep supervision [1].
2. The observed indices correlate with the optimal indices for all models and datasets, with the AF-0.5 model consistently exiting earlier than the LF one does.
Self-supervised Learning for Speech and Audio Processing I
Technical Program Session MLSP-3
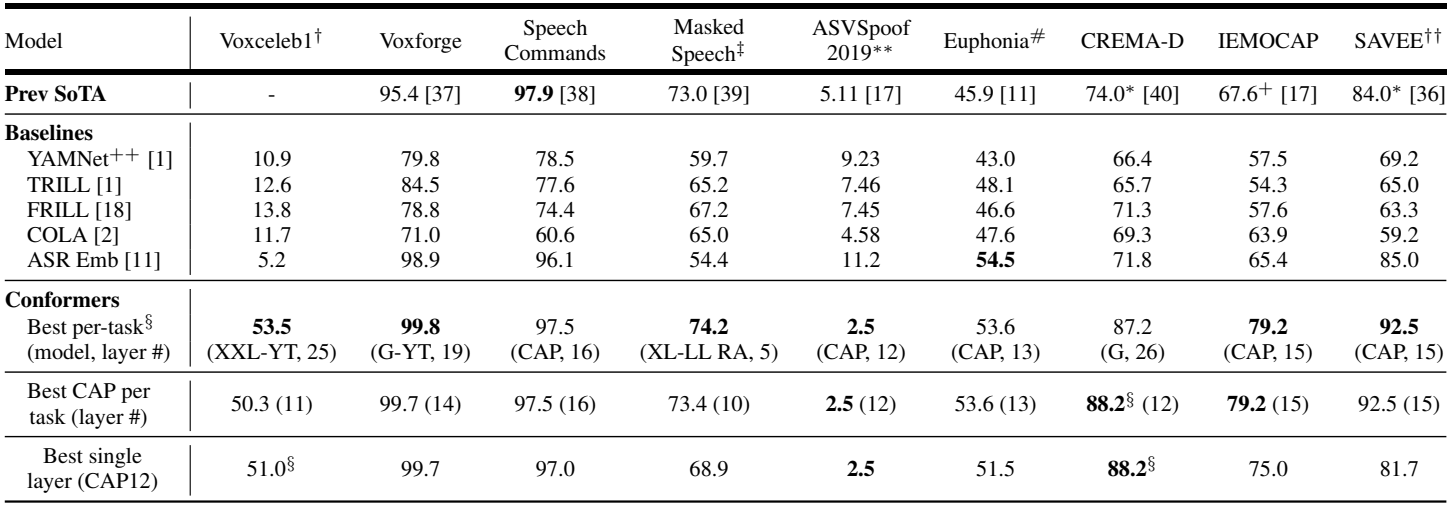
UNIVERSAL PARALINGUISTIC SPEECH REPRESENTATIONS USING SELF-SUPERVISED CONFORMERS
Verily Life Sciences, Boston, USA1 and Mountain View, California, USA
Many speech applications require understanding aspects beyond the words being spoken, such as recognizing emotion, detecting whether the speaker is wearing a mask, or distinguishing real from synthetic speech. In this work, we introduce a new state-of-the-art paralinguistic representation derived from large-scale, fully self-supervised training of a 600M+ parameter Conformer-based architecture. We benchmark on a diverse set of speech tasks and demonstrate that simple linear classifiers trained on top of our time-averaged representation outperform nearly all previous results, in some cases by large margins. Our analyses of context-window size demonstrate that, surprisingly, 2 second context-windows achieve 96% the performance of the Conformers that use the full long-term context on 7 out of 9 tasks. Furthermore, while the best per-task representations are extracted internally in the network, stable performance across several layers allows a single universal representation to reach near optimal performance on all tasks.
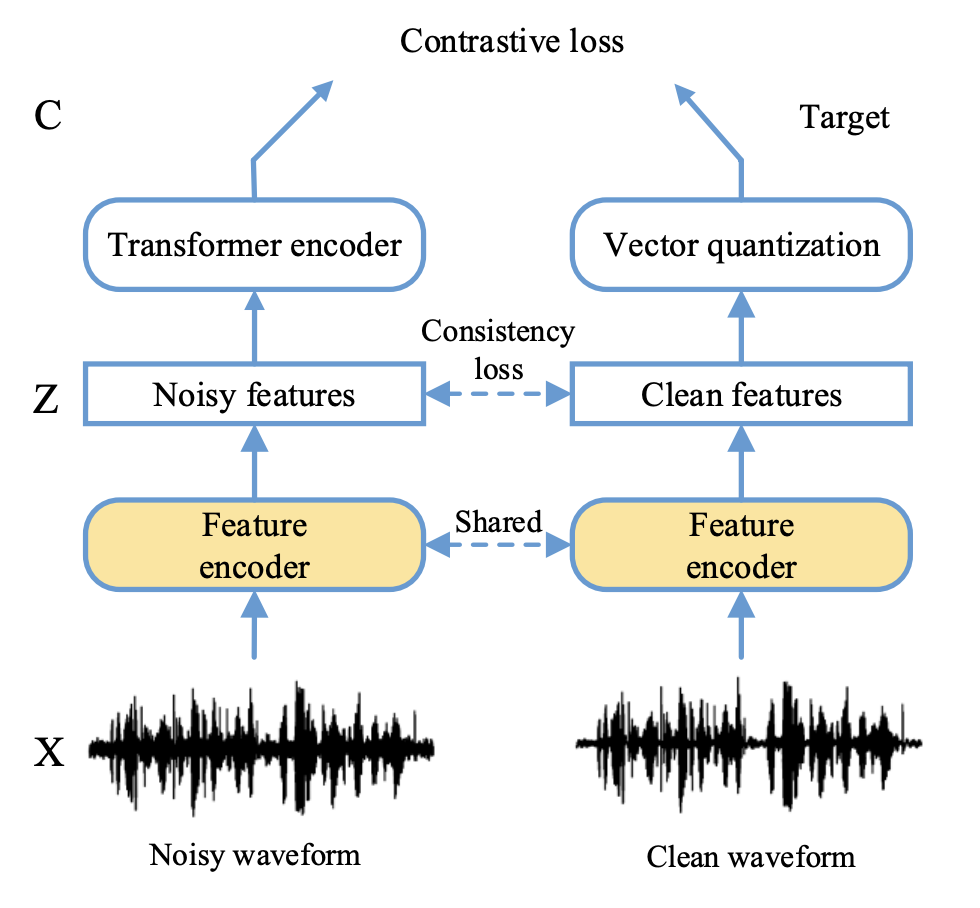
A NOISE-ROBUST SELF-SUPERVISED PRE-TRAINING MODEL BASED SPEECH REPRESENTATION LEARNING FOR AUTOMATIC SPEECH RECOGNITION
NEL-SLIP, University of Science and Technology of China (USTC), Hefei, China
Wav2vec2.0 is a popular self-supervised pre-training framework for learning speech representations in the context of automatic speech recognition (ASR). It was shown that wav2vec2.0 has a good robustness against the domain shift, while the noise robustness is still unclear. In this work, we therefore first analyze the noise robustness of wav2vec2.0 via experiments. We observe that wav2vec2.0 pre-trained on noisy data can obtain good representations and thus improve the ASR performance on the noisy test set, which however brings a performance degradation on the clean test set. To avoid this issue, in this work we propose an enhanced wav2vec2.0 model. Specifically, the noisy speech and the corresponding clean version are fed into the same feature encoder, where the clean speech provides training targets for the model. Experimental results reveal that the proposed method can not only improve the ASR performance on the noisy test set which surpasses the original wav2vec2.0, but also ensure a tiny performance decrease on the clean test set. In addition, the effectiveness of the proposed method is demonstrated under different types of noise conditions.
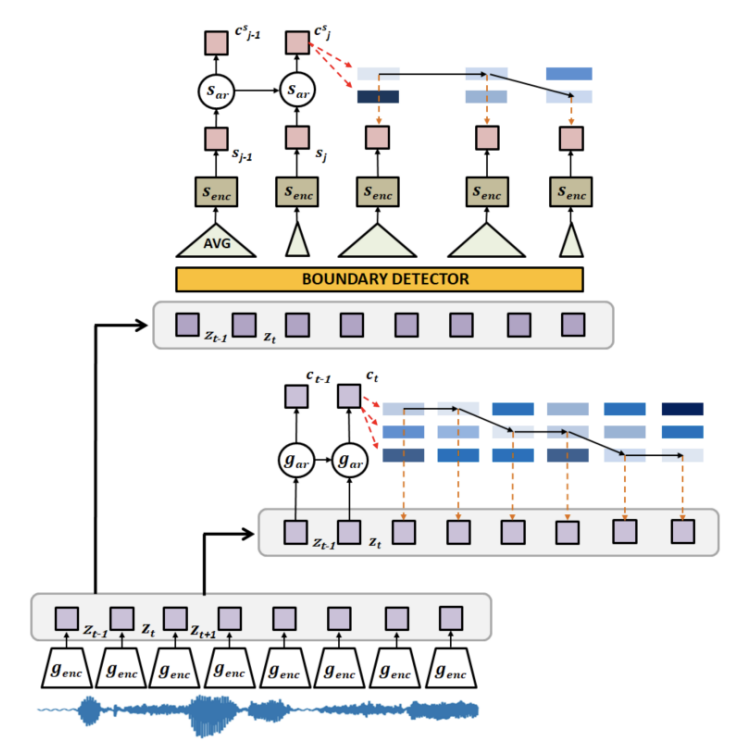
CONTRASTIVE PREDICTION STRATEGIES FOR UNSUPERVISED SEGMENTATION AND CATEGORIZATION OF PHONEMES AND WORDS
University of Wroclaw, Poland, NavAlgo, France, NVIDIA, Poland, Universite de Toulon, France
We identify a performance trade-off between the tasks of phoneme categorization and phoneme and word segmentation in several self-supervised learning algorithms based on Contrastive Predictive Coding (CPC). Our experiments suggest that context building networks, albeit necessary for high performance on categorization tasks, harm segmentation performance by causing a temporal shift on the learned representations. Aiming to tackle this trade-off, we take inspiration from the leading approaches on segmentation and propose multi-level Aligned CPC (mACPC). It builds on Aligned CPC (ACPC), a variant of CPC which exhibits the best performance on categorization tasks, and incorporates multi-level modeling and optimization for detection of spectral changes. Our methods improve in all tested categorization metrics and achieve state-of-the-art performance in word segmentation.
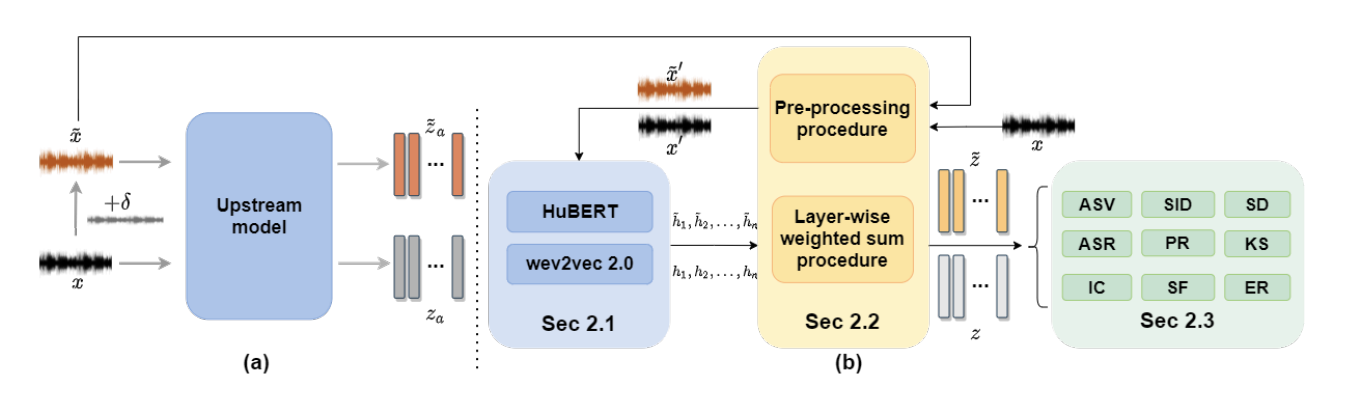
CHARACTERIZING THE ADVERSARIAL VULNERABILITY OF SPEECH SELF-SUPERVISED LEARNING
National Taiwan University, The Chinese University of Hong Kong
SUPERB
A leaderboard named Speech processing Universal PERformance Benchmark (SUPERB), which aims at benchmarking the performance of a shared self-supervised learning (SSL) speech model across various downstream speech tasks with minimal modification of architectures and a small amount of data, has fueled the research for speech representation learning. The SUPERB demonstrates speech SSL upstream models improve the performance of various downstream tasks through just minimal adaptation. As the paradigm of the self-supervised learning upstream model followed by downstream tasks arouses more attention in the speech community, characterizing the adversarial robustness of such paradigm is of high priority. In this paper, we make the first attempt to investigate the adversarial vulnerability of such paradigm under the attacks from both zero-knowledge adversaries and limited-knowledge adversaries. The experimental results illustrate that the paradigm proposed by SUPERB is seriously vulnerable to limited-knowledge adversaries, and the attacks generated by zero-knowledge adversaries are with transferability. The XAB test verifies the imperceptibility of crafted adversarial attacks.
CAPITALIZATION NORMALIZATION FOR LANGUAGE MODELING WITH AN ACCURATE AND EFFICIENT HIERARCHICAL RNN MODEL
Google Research
Problem
Capitalization normalization (truecasing) is the task of restoring the correct case (uppercase or lowercase) of noisy text.
Proposed method
A fast, accurate and compact two-level hierarchical word-and-character-based RNN
Used the truecaser to normalize user-generated text in a Federated Learning framework for language modeling.
Key Findings
In a real user A/B experiment, authors demonstrated that the improvement translates to reduced prediction error rates in a virtual keyboard application.
NEURAL-FST CLASS LANGUAGE MODEL FOR END-TO-END SPEECH RECOGNITION
Facebook AI, USA
Proposed method
Neural-FST Class Language Model (NFCLM) for endto-end speech recognition
a novel method that combines neural network language models (NNLMs) and finite state transducers (FSTs) in a mathematically consistent framework
Key Findings
NFCLM significantly outperforms NNLM by 15.8% relative in terms of WER.
NFCLM achieves similar performance as traditional NNLM and FST shallow fusion while being less prone to overbiasing and 12 times more compact, making it more suitable for on-device usage.
ENHANCE RNNLMS WITH HIERARCHICAL MULTI-TASK LEARNING FOR ASR
University of Missouri, USA
Proposed method
Key Findings
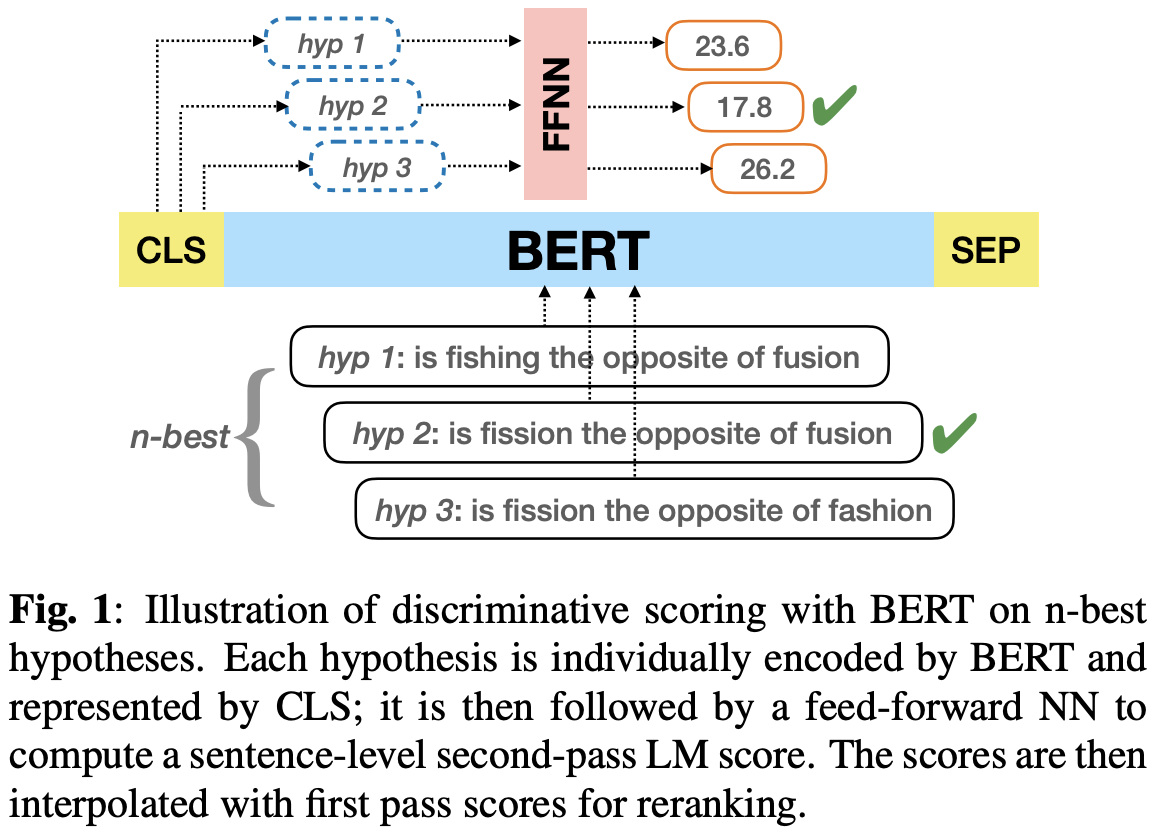
RESCOREBERT: DISCRIMINATIVE SPEECH RECOGNITION RESCORING WITH BERT
1Amazon Alexa AI, USA 2Emory University, USA
Problem
Second-pass rescoring improves the outputs from a first-pass decoder by implementing a lattice rescoring or n-best re-ranking.
Proposed method (RescoreBERT)
Authors showed how to train a BERT-based rescoring model with minimum WER (MWER) loss, to incorporate the improvements of a discriminative loss into fine-tuning of deep bidirectional pretrained models for ASR.
Authors proposed a fusion strategy that incorporates the MLM into the discriminative training process to effectively distill knowledge from a pretrained model. We further propose an alternative discriminative loss.
Key Findings
Reduced WER by 6.6%/3.4% relative on the LibriSpeech clean/other test sets over a BERT baseline without discriminative objective
Found that it reduces both latency and WER (by 3 to 8% relative) over an LSTM rescoring model.
Hybrid sub-word segmentation for handling long tail in morphologically rich low resource languages
Cognitive Systems Lab, University Bremen, Germany
Problem
Dealing with Out Of Vocabulary (OOV) words or unseen words
For morphologically rich languages having high type token ratio, the OOV percentage is also quite high.
Sub-word segmentation has been found to be one of the major approaches in dealing with OOVs.
Proposed method
This paper presents a hybrid sub-word segmentation algorithm to deal with OOVs.
A sub-word segmentation evaluation methodology is also presented.
All the experiments are done for conversational code-switched Malayalam-English corpus.
AUDIO-VISUAL MULTI-CHANNEL SPEECH SEPARATION, DEREVERBERATION AND RECOGNITION
The Chinese University of Hong Kong; Tencent AI lab
Problem
accurate recognition of cocktail party speech characterised by the interference from overlapping speakers, background noise and room reverberation.
Proposed method
In this paper, an audiovisual multi-channel speech separation, dereverberation and recognition approach with visual information into all three stages of the system is proposed.
The advantage of the additional visual modality over using audio only is demonstrated on two neural dereverberation approaches based on DNN-WPE and spectral mapping respectively.
BEST OF BOTH WORLDS: MULTI-TASK AUDIO-VISUAL AUTOMATIC SPEECH RECOGNITION AND ACTIVE SPEAKER DETECTION
Google, Inc.
Problem
Under noisy conditions, automatic speech recognition (ASR) can greatly benefit from the addition of visual signals coming from a video of the speaker’s face.
현실적으로 여러 얼굴이 존재하는 경우가 많은데 전통적으로 active speaker detection (ASD)으로 모든 시간마다 audio와 일치하는 active speaker's face를 분리하는 모델을 따로 사용했으나, 최근에는 attention 모델을 추가해서 별도의 ASD를 설계하지 않고 audio와 모든 face candidate을 모델에 집어 넣어 end-to-end way로 처리 하기도 한다.
Proposed method
2.1. A/V Backbone: Shared Audio-Visual Frontend
Acoustic Features. log mel filterbank
Audio and Video Synchronization. resample video
Visual Features. ConvNet on top of the synchronized video
Attention Mechanism. in order to soft-select the one matching the audio.
2.2. ASR Model - Transformer-Transducer Model
For ASR, the weighted visual features and input acoustic features are then concatenated along the last dimension, producing audio-visual features which are then fed to the ASR encoder.
2.3. ASD Model
For ASD, the attention scores is used directly for the model prediction. For each audio query and each timestep, the attention scores give a measure of how well each candidate video corresponds to the audio.
3. MULTI-TASK LOSS FOR A/V ASR AND ASD
ASD. For active speaker detection, the normalized attention weights can be used to train the attention module directly with cross entropy loss.
ASR. RNN-T loss
MTL Loss. We combine the ASD and ASR losses with a weighted linear sum of the losses
Key Findings
This paper presents a multi-task learning (MTL) for a model that can simultaneouslyperformaudio-visual ASR and active speaker detection, improving previous work on multiperson audio-visual ASR.
Combining the two tasks is enough to significantly improve the performance of the model in the ASD task relative to the baseline.
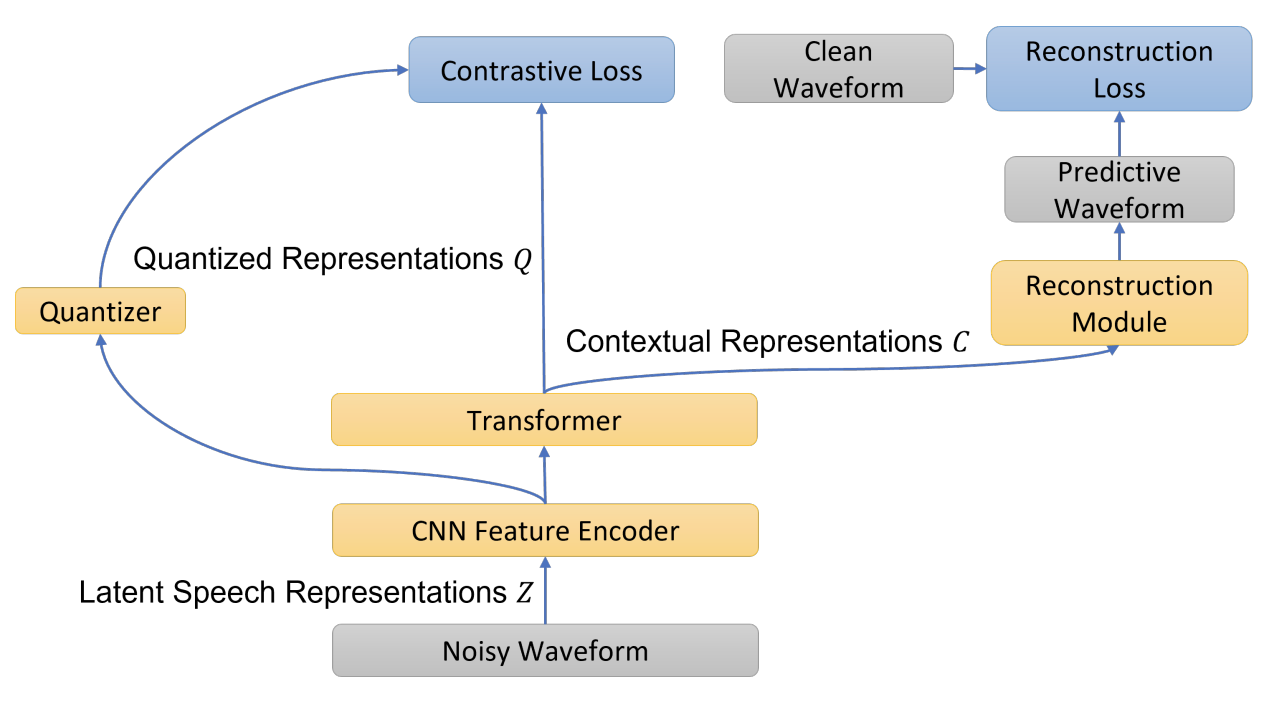
IMPROVING NOISE ROBUSTNESS OF CONTRASTIVE SPEECH REPRESENTATION LEARNING WITH SPEECH RECONSTRUCTION
The Ohio State University, USA, Microsoft Corporation
Problem
Noise Robust ASR
Proposed method
In this paper, authors employ a noise-robust representation learned by a refined self-supervised framework of wav2vec 2.0 for noisy speech recognition. They combine a reconstruction module with contrastive learning and perform multi-task continual pre-training to explicitly reconstruct the clean speech from the noisy input.