import torch
import torch.nn as nn
import torch.nn.functional as F
import math
classFullSelfAttention(nn.Module):"""
A vanilla multi-head self-attention layer with no masking and a projection at the end.
This implementation doesn't use causal masking, meaning all tokens can attend to each other.
"""def__init__(self, n_embd, n_head, attn_pdrop, resid_pdrop):
super().__init__()
assert n_embd % n_head == 0
self.n_head = n_head
# key, query, value projections for all heads
self.key = nn.Linear(n_embd, n_embd)
self.query = nn.Linear(n_embd, n_embd)
self.value = nn.Linear(n_embd, n_embd)
# regularization
self.attn_drop = nn.Dropout(attn_pdrop)
self.resid_drop = nn.Dropout(resid_pdrop)
# output projection
self.proj = nn.Linear(n_embd, n_embd)
defforward(self, x):
B, T, C = x.size()
# calculate query, key, values for all heads in batch and move head forward to be the batch dim
k = self.key(x).view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
q = self.query(x).view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
v = self.value(x).view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)# full self-attention; Self-attend: (B, nh, T, hs) x (B, nh, hs, T) -> (B, nh, T, T)
att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
att = F.softmax(att, dim=-1) # no masking here, full attention
att = self.attn_drop(att)
y = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)
y = y.transpose(1, 2).contiguous().view(B, T, C) # re-assemble all head outputs side by side# output projection
y = self.resid_drop(self.proj(y))
return y
Causal SelfAttention
classCausalSelfAttention(nn.Module):"""
A vanilla multi-head masked self-attention layer with a projection at the end.
It is possible to use torch.nn.MultiheadAttention here but I am including an
explicit implementation here to show that there is nothing too scary here.
"""def__init__(self, n_embd, block_size, n_head, attn_pdrop, resid_pdrop):
super().__init__()
assert n_embd % n_head == 0
self.n_head = n_head
# key, query, value projections for all heads
self.key = nn.Linear(n_embd, n_embd)
self.query = nn.Linear(n_embd, n_embd)
self.value = nn.Linear(n_embd, n_embd)
# regularization
self.attn_drop = nn.Dropout(attn_pdrop)
self.resid_drop = nn.Dropout(resid_pdrop)
# output projection
self.proj = nn.Linear(n_embd, n_embd)
# causal mask to ensure that attention is only applied to the left in the input sequence
self.register_buffer("mask", torch.tril(torch.ones(block_size, block_size))
.view(1, 1, block_size, block_size))
defforward(self, x, layer_past=None):
B, T, C = x.size()
# calculate query, key, values for all heads in batch and move head forward to be the batch dim
k = self.key(x).view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
q = self.query(x).view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
v = self.value(x).view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)# causal self-attention; Self-attend: (B, nh, T, hs) x (B, nh, hs, T) -> (B, nh, T, T)
att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
att = att.masked_fill(self.mask[:,:,:T,:T] == 0, float('-inf'))
att = F.softmax(att, dim=-1)
att = self.attn_drop(att)
y = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)
y = y.transpose(1, 2).contiguous().view(B, T, C) # re-assemble all head outputs side by side# output projection
y = self.resid_drop(self.proj(y))
return y
Look-ahead MHSA
Toimplement causal attention with a "look ahead" mechanism (i.e., allowing some future tokens to be attended to, while still maintaining causality by limiting how far into the future attention can extend), you can modify the attention mechanism to apply a causal mask with a specified number of future tokens.Here'sa PyTorch implementation of causal attention with look-ahead:```pythonimporttorchimporttorch.nn as nnimporttorch.nn.functional as FimportmathclassCausalAttentionWithLookAhead(nn.Module):"""Causalself-attention mechanism with a look-ahead window, allowing each token to attend to a limited numberoffuture tokens, while still maintaining the causal nature (i.e., no attention to tokens further ahead).Usage:
n_embd = 64 # embedding dimensionn_head = 8 # number of attention headsattn_pdrop = 0.1 # dropout for attention weightsresid_pdrop = 0.1 # dropout for output projectionlook_ahead_size = 2 # allow attention up to 2 future tokensmodel = CausalAttentionWithLookAhead(n_embd, n_head, attn_pdrop, resid_pdrop, look_ahead_size)x = torch.randn(16, 10, n_embd) # Batch of 16 sequences, each of length 10, embedding size 64output = model(x)print(output.size())# should return (16, 10, 64)"""def__init__(self, n_embd, n_head, attn_pdrop, resid_pdrop, look_ahead_size):super().__init__()assertn_embd % n_head == 0self.n_head = n_headself.look_ahead_size = look_ahead_size
# key, query, value projections for all headsself.key = nn.Linear(n_embd, n_embd)self.query = nn.Linear(n_embd, n_embd)self.value = nn.Linear(n_embd, n_embd)
# regularizationself.attn_drop = nn.Dropout(attn_pdrop)self.resid_drop = nn.Dropout(resid_pdrop)
# output projectionself.proj = nn.Linear(n_embd, n_embd)defforward(self, x):B,T, C = x.size()
# calculate query, key, values for all heads and move head forward to be the batch dimk = self.key(x).view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)q = self.query(x).view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)v = self.value(x).view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
# Causal attention with look ahead: Self-attend (B, nh, T, hs) x (B, nh, hs, T) -> (B, nh, T, T)att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
# Create the causal mask with a look-ahead windowcausal_mask = torch.tril(torch.ones(T, T), diagonal=self.look_ahead_size).view(1, 1, T, T).to(x.device) # (1, 1, T, T)att = att.masked_fill(causal_mask == 0, float('-inf'))
# Apply softmax and dropoutatt = F.softmax(att, dim=-1)att = self.attn_drop(att)
# Apply attention to the value: (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)y = att @ vy = y.transpose(1, 2).contiguous().view(B, T, C) # re-assemble all head outputs side by side
# Output projectiony = self.resid_drop(self.proj(y))returny
### Key Points:1.**Causal Masking with Look-Ahead**:-A causal mask is created using `torch.tril`, which generates a lower triangular matrix. The `diagonal=self.look_ahead_size` argument allows attention to future tokens within a window of size `look_ahead_size`. -For example, if `look_ahead_size=2`, each token will be able to attend to up to 2 future tokens in addition to past and current tokens.2.**Attention Calculation**:-As usual, the queries (`q`), keys (`k`), and values (`v`) are computed and reshaped for the multi-head attention operation.-The attention scores are computed by multiplying the query matrix with the transpose of the key matrix.-After masking, softmax is applied to obtain the attention weights, and these weights are used to compute a weighted sum of the values.3.**Handling the Future Look-Ahead**:-The `look_ahead_size` controls how many future tokens can be attended to. The larger the value, the further ahead the model can look while still being restricted by causality.
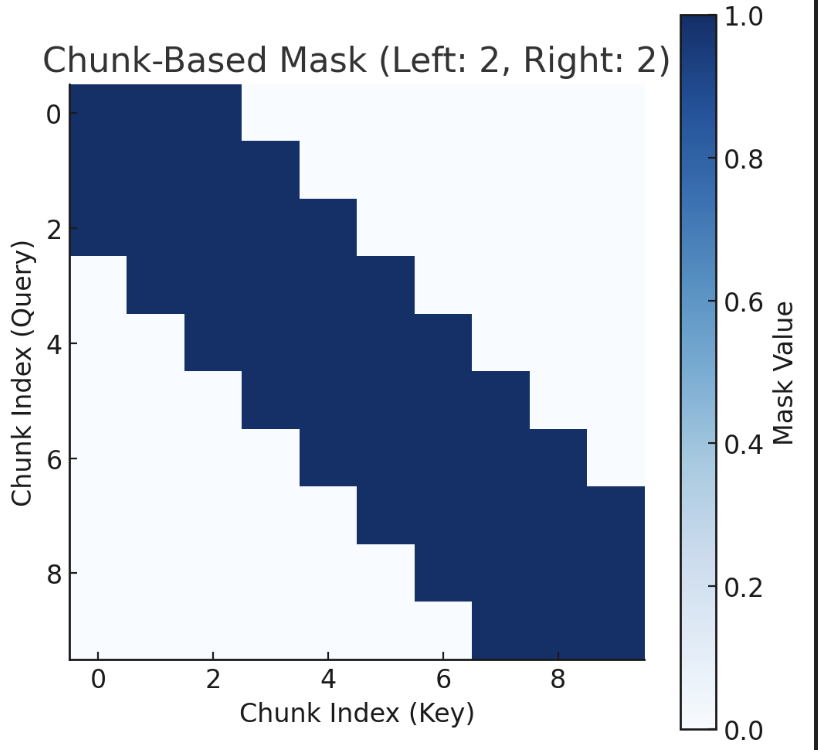
ChunkBasedAttention
Tomodify the `ChunkBasedAttention` implementation for parallel processing during training, the key change is to avoid sequential processing of chunks and instead process all chunks in parallel. This requires reshaping the input tensors so that the attention computation can be performed on all chunks simultaneously. Here's how you can adjust the `ChunkBasedAttention` class for parallel processing:
### Modified `ChunkBasedAttention` with Parallel Processing:```pythonimporttorchimporttorch.nn as nnimporttorch.nn.functional as FimportmathclassChunkBasedAttention(nn.Module):"""Chunk-basedself-attention mechanism with configurable left and right attention chunk sizes.Thisversion allows for parallel processing of chunks during training.ExampleUsage:n_embd = 64 # embedding dimensionn_head = 8 # number of attention headsattn_pdrop = 0.1 # dropout for attention weightsresid_pdrop = 0.1 # dropout for output projectionattention_chunk_size = 4 # size of each chunkleft_chunk_size = 1 # allow attention to 1 chunk on the leftright_chunk_size = 1 # allow attention to 1 chunk on the rightmodel = ChunkBasedAttention(n_embd, n_head, attn_pdrop, resid_pdrop, attention_chunk_size, left_chunk_size, right_chunk_size)x = torch.randn(16, 12, n_embd) # Batch of 16 sequences, each of length 12, embedding size 64output = model(x)print(output.size())# should return (16, 12, 64)"""def__init__(self, n_embd, n_head, attn_pdrop, resid_pdrop, attention_chunk_size, left_chunk_size, right_chunk_size):super().__init__()assertn_embd % n_head == 0self.n_head = n_headself.attention_chunk_size = attention_chunk_sizeself.left_chunk_size = left_chunk_sizeself.right_chunk_size = right_chunk_size
# key, query, value projections for all headsself.key = nn.Linear(n_embd, n_embd)self.query = nn.Linear(n_embd, n_embd)self.value = nn.Linear(n_embd, n_embd)
# regularizationself.attn_drop = nn.Dropout(attn_pdrop)self.resid_drop = nn.Dropout(resid_pdrop)
# output projectionself.proj = nn.Linear(n_embd, n_embd)defforward(self, x):B,T, C = x.size() # B: Batch size, T: Sequence length, C: Embedding dimensionchunk_size = self.attention_chunk_sizenum_chunks = (T + chunk_size - 1) // chunk_size # Total number of chunks
# calculate query, key, values for all heads and move head forward to be the batch dimk = self.key(x).view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)q = self.query(x).view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)v = self.value(x).view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
# Reshape the queries, keys, and values into chunks for parallel processingq_chunks = q.view(B, self.n_head, num_chunks, chunk_size, C // self.n_head) # (B, nh, num_chunks, chunk_size, hs)k_chunks = k.view(B, self.n_head, num_chunks, chunk_size, C // self.n_head) # (B, nh, num_chunks, chunk_size, hs)v_chunks = v.view(B, self.n_head, num_chunks, chunk_size, C // self.n_head) # (B, nh, num_chunks, chunk_size, hs)
# Construct the causal mask with left and right chunk sizeschunk_mask = torch.zeros(num_chunks, num_chunks).to(x.device)fori in range(num_chunks):start_idx = max(0, i - self.left_chunk_size)end_idx = min(num_chunks, i + self.right_chunk_size + 1)chunk_mask[i,start_idx:end_idx] = 1
# Apply the chunk mask to attention scoreschunk_mask = chunk_mask.view(1, 1, num_chunks, num_chunks) # (1, 1, num_chunks, num_chunks)
# Compute attention for all chunks in parallelattn_scores = torch.einsum('bhqnc,bhknc->bhqkn', q_chunks, k_chunks) / math.sqrt(C // self.n_head) # (B, nh, num_chunks, chunk_size, chunk_size)attn_scores = attn_scores.masked_fill(chunk_mask[:, :, None, :, :] == 0, float('-inf')) # Apply the chunk-based maskattn_probs = F.softmax(attn_scores, dim=-1) # (B, nh, num_chunks, chunk_size, chunk_size)attn_probs = self.attn_drop(attn_probs)
# Apply attention to the value: (B, nh, num_chunks, chunk_size, chunk_size) x (B, nh, num_chunks, chunk_size, hs)y_chunks = torch.einsum('bhqkn,bhknc->bhqnc', attn_probs, v_chunks) # (B, nh, num_chunks, chunk_size, hs)y = y_chunks.contiguous().view(B, self.n_head, T, C // self.n_head) # (B, nh, T, hs)y = y.transpose(1, 2).contiguous().view(B, T, C) # Reassemble all head outputs side by side
# Output projectiony = self.resid_drop(self.proj(y))returny
### Explanation of Changes:1.**Parallel Processing**:-Instead of processing each chunk sequentially, we reshape the input into chunks and process all chunks in parallel using `torch.einsum`. This allows for faster training with GPUs since parallelization is leveraged.2.**Causal Mask**:-A chunk-based mask is constructed to ensure that each chunk can only attend to its allowed left and right neighboring chunks.-This mask is then applied to the attention scores to ensure that attention is restricted to a specific range of chunks.3.**Efficient Attention Calculation**:-The attention scores are computed using `torch.einsum`, which efficiently handles the matrix multiplication for all chunks in parallel.-The `softmax` operation is applied across the appropriate dimension (`-1`), and then the attention probabilities are used to weight the values.4.**Reshaping for Output**:-After computing the attention-weighted values for all chunks, the output is reshaped back into the original sequence length to ensure consistency with the input format.
### Key Points:-**Chunk-Based Masking**: Each chunk can attend only to a specified range of chunks to the left and right, and this is enforced using the chunk mask.-**Parallel Computation**: By reshaping the input into chunks and using `torch.einsum`, we can compute attention for all chunks in parallel, which speeds up training.-**Flexibility**: The chunk size, left, and right attention window sizes are flexible and can be adjusted based on the model's requirements.