BEST-RQ: SSL with Random-projection Quantizer for Speech Recognition
BEST-RQ introduces a novel technique of self-supervised training using a combination of Random Projection Quantizer (RPQ) and Masked Language Modeling (MLM).
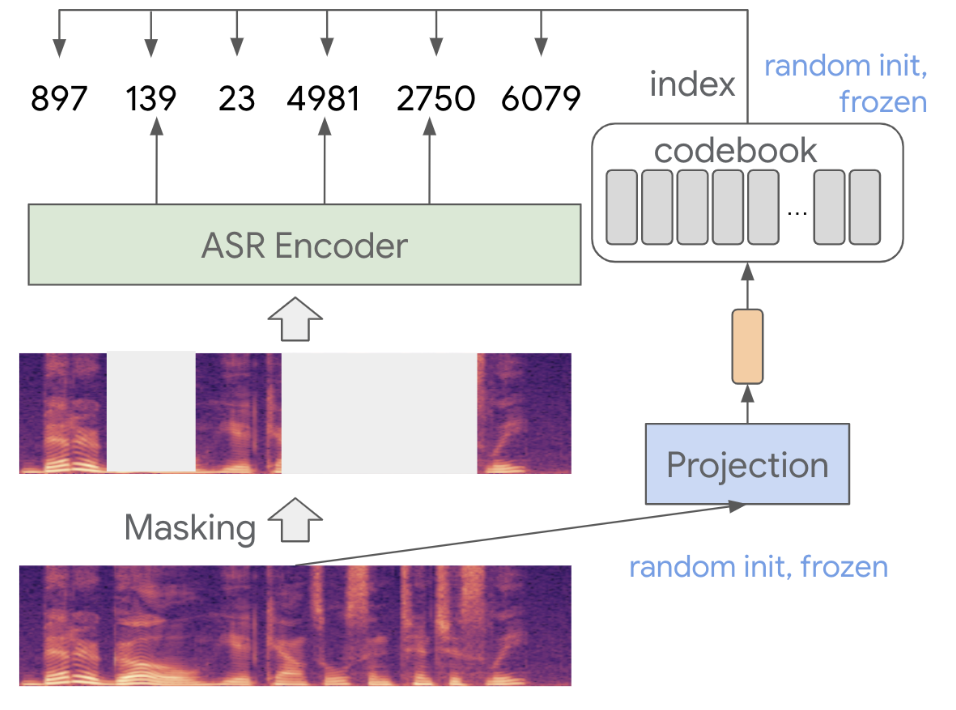
Entire process of BEST-RQ is firstly to proceed Random Projection Quantizer (RPQ) (randomly initialized linear layer and a single codebook for quantizing and discretizing the audio):
- The Mel filterbanks are projected through the linear layer.
- The index of the nearest codebook entry to the projection is selected as the target.
- The nearest codebook entry is found by calculating the argmin of the normalized distance between the projection and each codebook entry.
Afterward, a mask is applied to a portion of the Mel filterbanks, and the model’s objective is to predict the correct targets for the masked sections. This is framed as a classification task, and cross-entropy loss is used to compute the training objective.
1. Random Projection Quantizer (RPQ)
The Random Projection Quantizer is the core part in BEST-RQ, designed to discretize continuous speech features, making them suitable for BERT-like pretraining. RPQ consists of two major components: the Projection Matrix and the Codebook. Both are randomly initialized and remain fixed throughout the training process.
1) Projection Matrix
The projection matrix projects the original speech features into a lower-dimensional space. The matrix is of size ( d \times k ), where:
- d: Dimensionality of the original speech features (typically high, such as hundreds or thousands).
- k: Target dimensionality after projection (usually much lower than ( d )).
This dimensionality reduction is essential for handling the vast amount of speech data efficiently.
2) Codebook
The Codebook is a collection of n code vectors, each of size ( k ). These code vectors represent the discrete code space into which the speech features are projected.
- n: The size of the codebook, which can be tuned based on the task at hand.
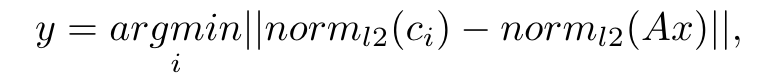
Given an input vector ( x ) (a ( d )-dimensional vector computed from speech signals), RPQ maps ( x ) to discrete labels ( y ) through the following operation:
Where:
- The projection matrix ( A ) is a randomly initialized ( h \times d ) matrix.
- The codebook ( C = {c_1, ..., c_n} ) contains randomly initialized ( h )-dimensional vectors.
- The function ( \text{norm}_{l2} ) denotes the L2 normalization.
This transformation enables the speech signals to be quantized into discrete labels, providing a structured learning signal for the downstream tasks.
The projection matrix is initialized using Xavier initialization (Glorot & Bengio, 2010).
The codebook is initialized using a standard normal distribution.
Both are kept frozen during the entire pretraining process, ensuring that the quantization remains consistent.
Code
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.linalg import vector_norm
class RandomProjectionQuantizer(nn.Module):
"""
Vector quantization using a projection and a randomly initialized codebook.
The output is the indices of the closest code in the codebook for each time step of the input.
Example
-------
>>> quantizer = RandomProjectionQuantizer(16, 16, 8192)
>>> inputs = torch.rand(10, 12, 16)
>>> output = quantizer(inputs)
>>> output.shape
torch.Size([10, 12])
"""
def __init__(self, input_dim, codebook_dim, codebook_vocab):
super().__init__()
self.input_dim = input_dim
self.codebook_dim = codebook_dim
self.codebook_vocab = codebook_vocab
# Initialize projection matrix with Xavier initialization
self.Prj_A_init = nn.init.xavier_uniform_(torch.empty((input_dim, codebook_dim)))
# Normalize a randomly initialized codebook
self.codebook = F.normalize(torch.randn(codebook_vocab, codebook_dim))
def forward(self, x):
"""
Forward the input through the projection and return the indices of the closest codebook entries.
"""
# Normalize the projected input
x = F.normalize(torch.matmul(x, self.Prj_A_init))
# Calculate distances between codebook entries and input, and find the closest code
distances = vector_norm(self.codebook.unsqueeze(1) - x.unsqueeze(1), dim=-1)
# Return the indices of the closest code for each input
return distances.argmin(dim=1)
2. Masked Language Modeling (MLM)
BEST-RQ applies Masked Language Modeling (MLM), much like BERT does for text, but in this case for speech. During training, certain portions of the speech signal are masked and replaced with noise.
- Masking Strategy: Each frame of speech is masked with a fixed probability, and the masked portions are replaced with noise sampled from a normal distribution (mean = 0, standard deviation = 0.1).
The model, typically based on a Transformer architecture, is then tasked with predicting the labels (codebook indices) of the masked speech based on the surrounding context. This allows the model to focus on learning robust speech representations.
** A unique point of BEST-RQ is that the RPQ's projection matrix and codebook are frozen and independent of the ASR encoder. This ensures that the model focuses solely on learning meaningful speech representations without needing to adapt to the intricacies of the quantization process.
Code
https://github.com/speechbrain/speechbrain/pull/2309/files#diff-a93bef3df2fb2e56565025e82dbc87ee2293c30872b211a91ea049fd6c3bb49dPre-train.
The pre-training uses mask length 400ms with masking probability of 0.01.
The learning rate schedule uses a transformer learning rate schedule (Vaswani et al., 2017).
Adam optimizer with 0.004 peak learning rate and 25000 warmup steps.
The batch size is 2048.
Since the encoder has 4 times temporal-dimension reduction, the quantization with random projections stacks every 4 frames for projections.
The vocab size of the codebook is 8192 and the dimension is 16.
The pre-training quality is not very sensitive to the codebook vocab size and the codebook dimension, and is more sensitive to the masking probability and the mask length. The role of the projection layer in the random-projection quantizer is to allow using different codebook dimensions, and one can achieve similar results without the projection and set the codebook dimension to be the same as the input dimension. Due to the variance coming from the random initialization, the impact of a hyperparameter usually requires multiple runs of experiments to verify the result.
Codebook utilization. One of the most critical factors for pre-training quality is the percentage of the codebook that is used during training. In particular, at each training step a higher percentage of the codebook being used in each batch correlates strongly with a good pre-training quality. When the distribution of the codebook utilization is skewed toward a smaller subset of codes, this usually makes the pre-training task easier and provides less effective pre-training. The l2 normalizations on the projected vector and the codebook are critical for providing more uniform codebook utilization. On the other hand, using randomly initialized codebook and projection matrix can introduce different codebook utilizations with different random seeds, which impact the pretraining quality across different runs with same experiment configurations. This variance impacts quality more when training with smaller pre-training and fine-tuning datasets. How to reduce this reproducibility issue caused by random initialization is an important next step for improving random-projection quantizations.
Initialization. The quantizer uses random initialization and does not update the parameters, and therefore the initialization algorithm can play an important role on the results. In this paper we showed results with Xavier initialization for the projection matrix and the standard normal distribution for the codebook, and further comparisons on different initialization algorithms can be conduct in the future work.
[1] https://arxiv.org/pdf/2202.01855
[2] https://arxiv.org/pdf/2405.04296
[3] Speechbrain