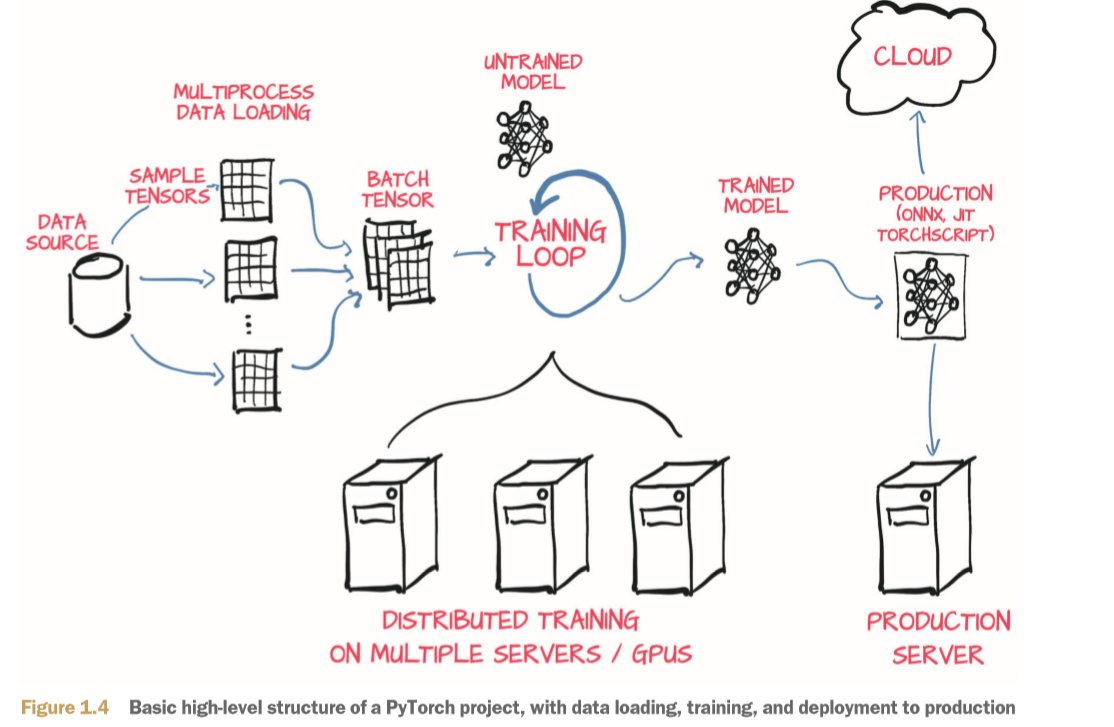
Intro
딥러닝 모델을 설계하고 개발할 때 중요한 부분 중 하나인 데이터 로더 만드는 방법에 대해서 정리하고자 한다.
특별히, 음성이나 음악 등 연속적인 데이터를 이용하는 모델을 구축하고자 한다.
신호를 가지고 할 수 있는 것들이 많이 있지만, 우선 Keyword Spotting 알고리즘을 만드는 것을 목표로 놓고, 그에 맞는 데이터 로더를 만들어 가보도록 하자.
먼저 shell 환경에서 다음과 같이 tensorflow speech command dataset을 다운로드 받자.
!wget https://storage.cloud.google.com/download.tensorflow.org/data/speech_commands_v0.02.tar.gz
torch.utils.data.Dataset 은 데이터셋을 나타내는 추상 클래스이다. 우리가 만드는 Custom Dataset Class 는 torch.utils.data.Dataset 을 상속하고, 다음 3가지 멤버함수들을 오버라이드 해야 한다.
import torch
class CustomDataset(torch.utils.data.Dataset):
def __init__(self, ...):
def __len__(self):
def __getitem__(self, idx):
멤버함수 __init__() 는 클래스 인스턴스 생성시 파라미터로 들어오는 정보로 원하는 데이터셋 정보를 초기화 해야 한다.
len(dataset) 에서 호출되는, 멤버함수 __len__ 은 데이터 셋의 크기를 return 해야 한다.
dataset[i] 에서 호출되는, __getitem__ 은 i 번째 샘플을 찾는데 사용된다.
그럼 Custom Dataset Class인 SpeechCommandsDataset 를 만들어 보자.
import torch
import os
import numpy as np
import librosa
CLASSES = 'unknown, silence, yes, no, up, down, left, right, on, off, stop, go'.split(', ')
class SpeechCommandsDataset(torch.utils.data.Dataset):
"""Google speech commands dataset. Only 'yes', 'no', 'up', 'down', 'left',
'right', 'on', 'off', 'stop' and 'go' are treated as known classes.
All other classes are used as 'unknown' samples.
"""
def __init__(self, folder, transform=None, classes=CLASSES, silence_percentage=0.1):
"""
Args:
folder (string): Path folder.
transform (callable, optional): Optional transform to be applied
on a sample.
class (string): list
"""
all_classes = [d for d in os.listdir(folder) if os.path.isdir(os.path.join(folder, d)) and not d.startswith('_')]
class_to_idx = {classes[i]: i for i in range(len(classes))}
for c in all_classes:
if c not in class_to_idx:
class_to_idx[c] = 0
data = []
for c in all_classes:
d = os.path.join(folder, c)
target = class_to_idx[c]
for f in os.listdir(d):
path = os.path.join(d, f)
data.append((path, target))
# add silence
target = class_to_idx['silence']
data += [('', target)] * int(len(data) * silence_percentage)
self.classes = classes
self.data = data
self.transform = transform
def __len__(self):
return len(self.data)
def __getitem__(self, index):
path, target = self.data[index]
data = {'path_wave': path, 'target': target}
if self.transform is not None:
data = self.transform(data)
return data
__init__ 을 사용해서 폴더 안에 있는 데이터들의 Path 를 읽지만, __getitem__ 을 이용해서 그 path에 해당하는 waveform 데이터를 읽어드린다 . 이 방법은 모든 파일을 메모리에 저장하지 않고 필요할때마다 읽기 때문에 메모리를 효율적으로 사용한다.
데이터셋의 샘플은 {'path': path_wave, 'target': label} 의 사전 형태를 갖는다. 선택적 인자인 transform 을 통해 필요한 전처리 과정을 샘플에 적용할 수 있다. transform 에 대해서는 뒷부분에서 조금 더 자세히 살펴보기로 한다.
클래스를 인스턴스화 하고, 데이터 샘플을 통해서 반복한다. 첫번째 4개의 크기를 출력하고, 샘플들의 wave와 target을 보여준 것이다.
path_dataset = "~/data_speech_commands_v0.02"
dataset = SpeechCommandsDataset(path_dataset)
for i in range(len(dataset)):
sample = dataset[i]
print(i, sample['path_wave'], sample['target'])
Out:
0 /Users/Downloads/data_speech_commands_v0.02/right/8e523821_nohash_2.wav 7
1 /Users/Downloads/data_speech_commands_v0.02/right/bb05582b_nohash_3.wav 7
2 /Users/Downloads/data_speech_commands_v0.02/right/988e2f9a_nohash_0.wav 7
3 /Users/Downloads/data_speech_commands_v0.02/right/a69b9b3e_nohash_0.wav 7
...
Transform
뉴럴 네트워크 학습을 위해서 우리는 다양한 형태의 데이터 변환이 필요할 수 있다. 예를들어, 음성 신호처리에서는 다음과 같은 다양한 transforms이 필요하다.
- 음성 신호를 time domain 혹은 frequency domain 에서 분석해야 한다.
- 모든 wave 파일의 길이가 상이한 특성 때문에 파일들의 길이를 Fix 하여 데이터를 재구성 한 후, 원하는 뉴럴네트워크 모델을 학습해야 한다.
- Data augmentation 적용 ( Time Streching / Shift / Add Noise )
모든 transform 은 클래스로 작성하여 클래스가 호출될 때마다 Transform의 매개변수가 전달 되지 않아도 되게 만드는 것이 좋다. 이를 위해 __call__ 함수와 __init__ 함수를 포함한 목적에 맞는 클래스를 구현한다.
이 페이지에서는 4가지 Transform 클래스를 구현한다.
- LoadAudio : Audio를 librosa library를 사용하여 time domain data로 로드한다.
- FixAudioLength : time domain audio 신호를 1초를 기준으로 zero-padding 하거나, truncates 시켜서 fixed length로 변환한다.
- ToMelSpectrogram : time domain 신호로부터 freqency domain log Mel filterbank 특징벡터로 변경한다.
- ToTensor : numpy 벡터를 torch tensor type 으로 변경한다.
import torch
import librosa
import numpy as np
class LoadAudio(object):
"""Loads an audio into a numpy array."""
def __init__(self, sample_rate=16000):
self.sample_rate = sample_rate
def __call__(self, data):
path = data['path']
if path:
samples, sample_rate = librosa.load(path, self.sample_rate)
else:
# silence
sample_rate = self.sample_rate
samples = np.zeros(sample_rate, dtype=np.float32)
data['samples'] = samples
data['sample_rate'] = sample_rate
return data
class FixAudioLength(object):
"""Either pads or truncates an audio into a fixed length."""
def __init__(self, time=1):
self.time = time
def __call__(self, data):
samples = data['samples']
sample_rate = data['sample_rate']
length = int(self.time * sample_rate)
if length < len(samples):
data['samples'] = samples[:length]
elif length > len(samples):
data['samples'] = np.pad(samples, (0, length - len(samples)), "constant")
return data
class ToMelSpectrogram(object):
"""Creates the mel spectrogram from an audio. The result is a 32x32 matrix."""
def __init__(self, n_mels=32):
self.n_mels = n_mels
def __call__(self, data):
samples = data['samples']
sample_rate = data['sample_rate']
s = librosa.feature.melspectrogram(samples, sr=sample_rate, n_mels=self.n_mels)
data['mel_spectrogram'] = librosa.power_to_db(s, ref=np.max)
return data
class ToTensor(object):
"""Converts into a tensor."""
def __init__(self, np_name, tensor_name, normalize=None):
self.np_name = np_name
self.tensor_name = tensor_name
self.normalize = normalize
def __call__(self, data):
tensor = torch.FloatTensor(data[self.np_name])
if self.normalize is not None:
mean, std = self.normalize
tensor -= mean
tensor /= std
data[self.tensor_name] = tensor
return data
Transform 구성(Compose)
Trasform 들이 잘 작성되었나 확인해보자.
위에 정의한 클래스들을 사용하여, path_wave로부터 raw audio data를 메모리로 load 하고 1초 기준으로 zero-padding/truncate 하고, MelSpectrogram으로 변환 후 Torch Tensor 타입으로 변경한다.
torchvision.transforms.Compose 는 위의 클래스에 정의 일을 하도록 호출할 수 있는 클래스이다.
from torchvision import transforms
n_mels=40
batch_size=4
use_gpu=False
num_dataloader_workers_=1
path_dataset = "/Users/Downloads/data_speech_commands_v0.02"
dataset = SpeechCommandsDataset(path_dataset)
_loadaudio = LoadAudio()
_fixaudiolength = FixAudioLength()
_melSpec = ToMelSpectrogram()
composed = transforms.Compose([LoadAudio(),
FixAudioLength(),
ToMelSpectrogram(n_mels=n_mels),
ToTensor('mel_spectrogram', 'input')])
sample = dataset[0]
transformed_sample = _loadaudio(sample)
print(transformed_sample['samples'])
transformed_sample = _fixaudiolength(sample)
print(transformed_sample['samples'])
transformed_sample = _melSpec(sample)
print(transformed_sample['mel_spectrogram'])
transformed_sample = composed(sample)
print(transformed_sample['path_wave'], transformed_sample['input'].size(), transformed_sample['target'])
Out:
[ 0.0000000e+00 0.0000000e+00 -3.0517578e-05 ... -6.1035156e-05
-6.1035156e-05 -6.1035156e-05]
[ 0.0000000e+00 0.0000000e+00 -3.0517578e-05 ... -6.1035156e-05
-6.1035156e-05 -6.1035156e-05]
[[-80. -80. -80. ... -80. -80. -80. ]
[-76.06169 -78.95192 -80. ... -80. -80. -80. ]
[-80. -80. -80. ... -80. -80. -80. ]
...
[-80. -80. -80. ... -80. -80. -80. ]
[-80. -80. -80. ... -80. -80. -80. ]
[-80. -80. -80. ... -80. -80. -80. ]]
/Users/Downloads/data_speech_commands_v0.02/right/8e523821_nohash_2.wav torch.Size([40, 32]) 7
Custom dataset에 적용
이제 Transform 클래스들을 기본 custom dataset 클래스에 적용해보자.
from torchvision import transforms
from tqdm import tqdm
n_mels=40
batch_size=4
use_gpu=False
num_dataloader_workers=1
# path_dataset = "~/data_speech_commands_v0.02"
path_dataset = "/Users/Downloads/data_speech_commands_v0.02"
dataset = SpeechCommandsDataset(path_dataset,
transforms.Compose([LoadAudio(),
FixAudioLength(),
ToMelSpectrogram(n_mels=n_mels),
ToTensor('mel_spectrogram', 'input')]))
dataloader = torch.utils.data.DataLoader(dataset,
batch_size=batch_size,
shuffle=False,
pin_memory=use_gpu,
num_workers=num_dataloader_workers)
for batch in tqdm(dataloader, unit="audios", unit_scale=dataloader.batch_size):
inputs = batch['input']
targets = batch['target']
print(inputs.size(), targets.size())
요약
wave 파일 전체를 메모리에 올리지 않고 필요할 때마다 로드 시키고, 원하는 형태의 데이터로 transform을 메모리상에서 할 수 있다.
전체 코드 공유
import torch
import os
import librosa
import numpy as np
from torchvision import transforms
from tqdm import tqdm
CLASSES = 'unknown, silence, yes, no, up, down, left, right, on, off, stop, go'.split(', ')
class SpeechCommandsDataset(torch.utils.data.Dataset):
"""Google speech commands dataset. Only 'yes', 'no', 'up', 'down', 'left',
'right', 'on', 'off', 'stop' and 'go' are treated as known classes.
All other classes are used as 'unknown' samples.
"""
def __init__(self, folder, transform=None, classes=CLASSES, silence_percentage=0.1):
"""
Args:
folder (string): Path folder.
transform (callable, optional): Optional transform to be applied
on a sample.
class (string): list
"""
all_classes = [d for d in os.listdir(folder) if os.path.isdir(os.path.join(folder, d)) and not d.startswith('_')]
class_to_idx = {classes[i]: i for i in range(len(classes))}
for c in all_classes:
if c not in class_to_idx:
class_to_idx[c] = 0
data = []
for c in all_classes:
d = os.path.join(folder, c)
target = class_to_idx[c]
for f in os.listdir(d):
path = os.path.join(d, f)
data.append((path, target))
# add silence
target = class_to_idx['silence']
data += [('', target)] * int(len(data) * silence_percentage)
self.classes = classes
self.data = data
self.transform = transform
def __len__(self):
return len(self.data)
def __getitem__(self, index):
path, target = self.data[index]
data = {'path_wave': path, 'target': target}
if self.transform is not None:
data = self.transform(data)
return data
class LoadAudio(object):
"""Loads an audio into a numpy array."""
def __init__(self, sample_rate=16000):
self.sample_rate = sample_rate
def __call__(self, data):
path = data['path_wave']
if path:
samples, sample_rate = librosa.load(path, self.sample_rate)
else:
# silence
sample_rate = self.sample_rate
samples = np.zeros(sample_rate, dtype=np.float32)
data['samples'] = samples
data['sample_rate'] = sample_rate
return data
class FixAudioLength(object):
"""Either pads or truncates an audio into a fixed length."""
def __init__(self, time=1):
self.time = time
def __call__(self, data):
samples = data['samples']
sample_rate = data['sample_rate']
length = int(self.time * sample_rate)
if length < len(samples):
data['samples'] = samples[:length]
elif length > len(samples):
data['samples'] = np.pad(samples, (0, length - len(samples)), "constant")
return data
class ToMelSpectrogram(object):
"""Creates the mel spectrogram from an audio. The result is a 32x32 matrix."""
def __init__(self, n_mels=32):
self.n_mels = n_mels
def __call__(self, data):
samples = data['samples']
sample_rate = data['sample_rate']
s = librosa.feature.melspectrogram(samples, sr=sample_rate, n_mels=self.n_mels)
data['mel_spectrogram'] = librosa.power_to_db(s, ref=np.max)
return data
class ToTensor(object):
"""Converts into a tensor."""
def __init__(self, np_name, tensor_name, normalize=None):
self.np_name = np_name
self.tensor_name = tensor_name
self.normalize = normalize
def __call__(self, data):
tensor = torch.FloatTensor(data[self.np_name])
if self.normalize is not None:
mean, std = self.normalize
tensor -= mean
tensor /= std
data[self.tensor_name] = tensor
return data
n_mels=40
batch_size=4
use_gpu=False
num_dataloader_workers=1
path_dataset = "/Users/Downloads/data_speech_commands_v0.02"
dataset = SpeechCommandsDataset(path_dataset,
transforms.Compose([LoadAudio(),
FixAudioLength(),
ToMelSpectrogram(n_mels=n_mels),
ToTensor('mel_spectrogram', 'input')]))
dataloader = torch.utils.data.DataLoader(dataset,
batch_size=batch_size,
shuffle=False,
pin_memory=use_gpu,
num_workers=num_dataloader_workers)
for batch in tqdm(dataloader, unit="audios", unit_scale=dataloader.batch_size):
inputs = batch['input']
targets = batch['target']
print(inputs.size(), targets.size())