Model Overview
- Whisper is a Transformer-based encoder-decoder model.
Training Data
- Whisper ASR models are trained on a mixture of English-only and multilingual data, with a substantial amount of weakly labeled and pseudolabeled audio.
Whisper ASR V1 and V2
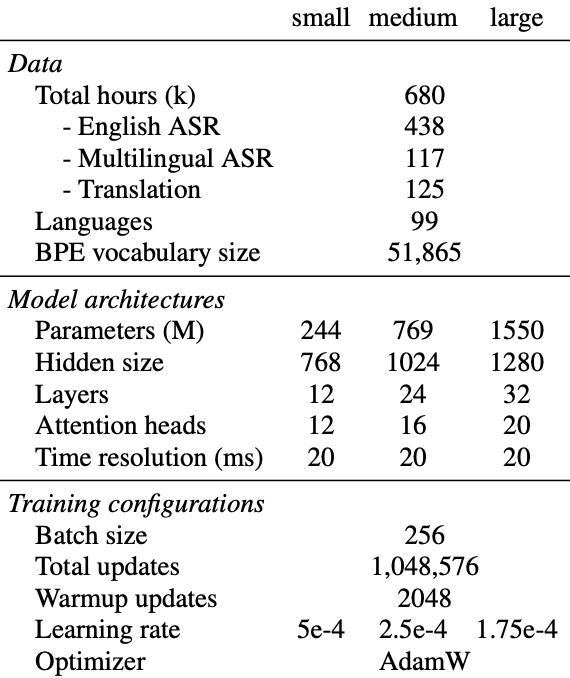
- Trained on 680,000 hours of audio and corresponding transcripts from the internet.
- Data distribution includes 65% English audio (438k hours), 18% non-English audio with English transcripts, and 17% non-English audio with corresponding transcripts, spanning 98 languages.
Whisper ASR V3
- Trained on 1 million hours of weakly labeled audio and 4 million hours of pseudolabeled audio of pseudolabeled audio collected using Whisper large-v2. The model was trained for 2.0 epochs over this mixture dataset.
- V3 shows a 10% to 20% reduction in errors compared to V2
Training Details
- Initial models were trained with AdamW optimizer, gradient norm clipping, and a linear learning rate decay after a warmup period.
- No data augmentation or regularization was used initially due to the diversity and size of the dataset.
- For Whisper Large V2, additional techniques like SpecAugment, Stochastic Depth, and BPE Dropout were introduced for regularization.
- Different max learning rates were used for different model sizes.
Hyperparameters
General Hyperparameters
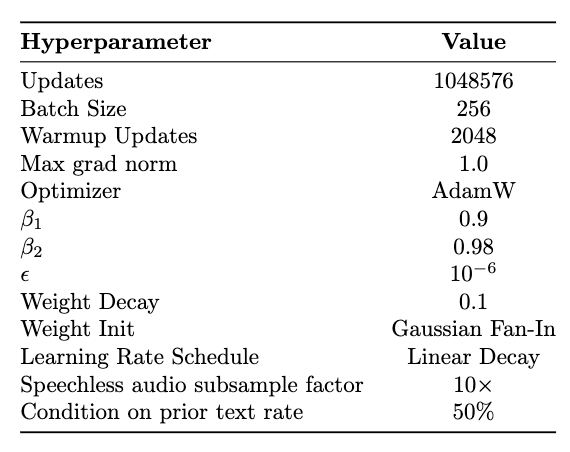
Hyperparameters for Whisper Large V2

Model Learning Rates

Summary
'Speech Signal Processing > Speech Recognition' 카테고리의 다른 글
| [DataLoader] DynamicBatchSampler (3) | 2024.10.09 |
|---|---|
| Text-only adaptation for E2E ASR models (0) | 2024.04.04 |
| Subword modelling for ASR (0) | 2022.05.07 |
| [Kaldi Decoding] 칼디 디코딩 그래프 구성 (0) | 2020.06.18 |
| [Kaldi Decoding] Finite State Transducer algorithms (FST) (0) | 2020.06.18 |