K. Han et al, "Deep Neural Network Based Spectral Feature Mapping for Robust Speech Recognition," Interspeech 2015. [1]
-일반적으로 사용되는 DNN, LSTM, CNN을 이용한 spectral feature mapping 논문들은 성능 측정 measure로 PESQ, SDR, STOI 등을 제시, but 최종 ASR을 위한 WER measure 측면에서 성능 향상을 원함-> DL 구조 output 을 일반적인 filterbank or MFCC 로 사용함.
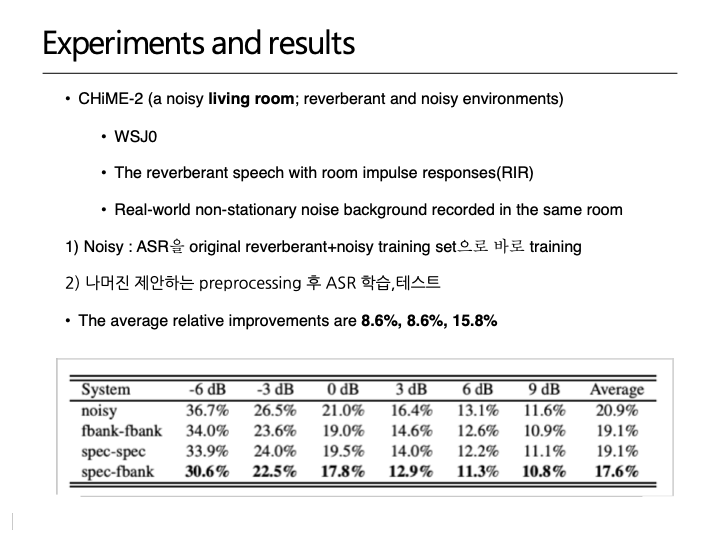
- CHiME-2 noisy living room reverberant & noisy 로 테스트

K. Wang et al, "Investigating Generative Adversarial Networks based Speech Dereverberation for Robust Speech Recognition," Interspeech 2018. [2]
- GAN의 Generator을 반향 제거를 위한 enhancer로 사용.
- 위의 논문의 결과대로 G의 output 은 MFCC 를 사용함
- GAN training을 위해 LSGAN, CGAN 등을 시도
- 샤오미 논문으로, 데이터는 연구용이 아닌 실제 서비스를 위한 많은 데이터 사용.
- ASR 을 위한 데이터 따로 존재. 클린으로만 ASR AM training, Multi-condition Training (MCT)- noisy로도 ASR AM training 따로 실험.



사진 설명을 입력하세요.
[1] K. Han et al, "Deep Neural Network Based Spectral Feature Mapping for Robust Speech Recognition," Interspeech 2015.
[2] K. Wang et al, "Investigating Generative Adversarial Networks based Speech Dereverberation for Robust Speech Recognition," Interspeech 2018.
'Speech Signal Processing > Applications' 카테고리의 다른 글
| [Source Separation] SUDO RM -RF (0) | 2020.08.28 |
|---|---|
| [Acoustic Echo Cancellation] AEC and RES problems (0) | 2020.08.16 |
| [Speech Emotion Recognition] ICASSP 2020 (0) | 2020.08.05 |
| [Source Separation] Wave-U-Net (1) | 2020.07.19 |
| [E2E Keyword Spotting] End-to-End Streaming Keyword Spotting (0) | 2020.06.13 |