개요
음성 인식, 음성 합성, 오디오 신호 처리 등의 기술을 익히기 위해서는 신호에 대한 기본적인 지식과 컴퓨터 상에서 다룰 수 있는 능력이 있어야 합니다. 신호는 시간 영역과 주파수 영역에서 분석할 수 있으며 파이썬으로 Librosa 라이브러리를 사용하여 손쉽게 분석이 가능합니다.
오디오 파일 Load
오디오 파일은 일반적으로 wav, pcm 등의 형식으로 저장되며 sampling 개념을 사용하여 디지털화 됩니다. 오디오 데이터 처리를 위해 대표적으로 사용하는 Python 라이브러리는 librosa 입니다. librosa를 사용하여, 오디오 파일을 로드 해보겠습니다.
import librosa
audio_data = 'example.wav'
# 오디오 파일은 명시된 특정 샘플 속도 (sr)로 샘플링 된 후 NumPy 배열로 load 된다.
x = librosa.load(audio_data, sr=16000)
The sampling rate (sr) 는 sound의 초당 sample (data points) 수 입니다. 예를 들어 sampling frequency가 44kHz 인 경우 60 초 길이의 파일은 2,646,000(44000*60) 개의 샘플로 구성되어 있습니다.
시간 영역(TIme-domain) 에서 분석
일반적으로 음성/오디오 신호는 시간영역과 주파수영역에서 분석을 할 수 있습니다. 위에서 메모리 상에 load한 샘플링된 신호(데이터)를 시간영역에서 시간에 따른 파형의 진폭을 표현 해보겠습니다.
신호를 시각화하고 plotting 하기 위해 Python 시각화 대표 라이브러리인 Matplotlib 를 사용합니다.
import matplotlib.pyplot as plt
import librosa.display
plt.figure(figsize=(14, 5))
librosa.display.waveplot(x, sr=16000)
주파수 영역(Frequency-domain) 에서 분석
다음으로 주파수 영역에서 신호를 그려보겠습니다.
spectrogram을 사용하면 시간에 따라 주파수 스펙트럼이 어떻게 변화하는지 확인할 수 있습니다.
spectrogram : 시간에 따라 변화하는 신호의 주파수 스펙트럼의 크기를 시각적으로 표현한 것
librosa 라이브러리에 포함되어 있는 "Short Time Fourier Transform (STFT)" 를 사용하여 시간영역의 값을 주파수 영역에서 표현한 것입니다. STFT를 통해 구할 수 있는 값은 magnitude, phase로 나눌 수 있고, spectrogram은 magnitude만 가지고, 시간축에 대해서 표현하는 것입니다. abs()함수를 통해 magnitude를 구한후 db scale로 변경하여 다음과 같이 시간에 따른 스펙트럼의 크기를 확인할 수 있습니다.
X = librosa.stft(x)
X_mag = abs(X)
# energy levels(dB) 로 변경
Xdb = librosa.amplitude_to_db(X_mag)
plt.figure(figsize=(20, 5))
librosa.display.specshow(Xdb, sr=16000, x_axis='time', y_axis='hz')
plt.colorbar()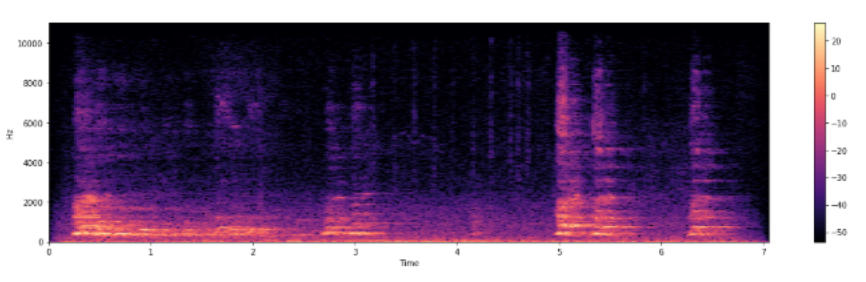
'Speech Signal Processing > Basic' 카테고리의 다른 글
| Public Speech Datasets for ASR (0) | 2023.11.18 |
|---|---|
| Public Speech Datasets for ASR (details) (0) | 2023.11.18 |
| 16 Bit, 16kHz wav 데이터 사이즈 계산 (Calculation of 16 Bit, 16kHz wave data size) (0) | 2021.05.14 |
| 16비트 고정소수점, 32비트 부동소수점 WAV 파일 (16-bit fixed point, 32-bit floating point WAV file basics) (0) | 2020.07.22 |
| [Microphones] 제품 개발을 위한 엔지니어링 마이크 선택 시 참고사항 (0) | 2020.06.18 |